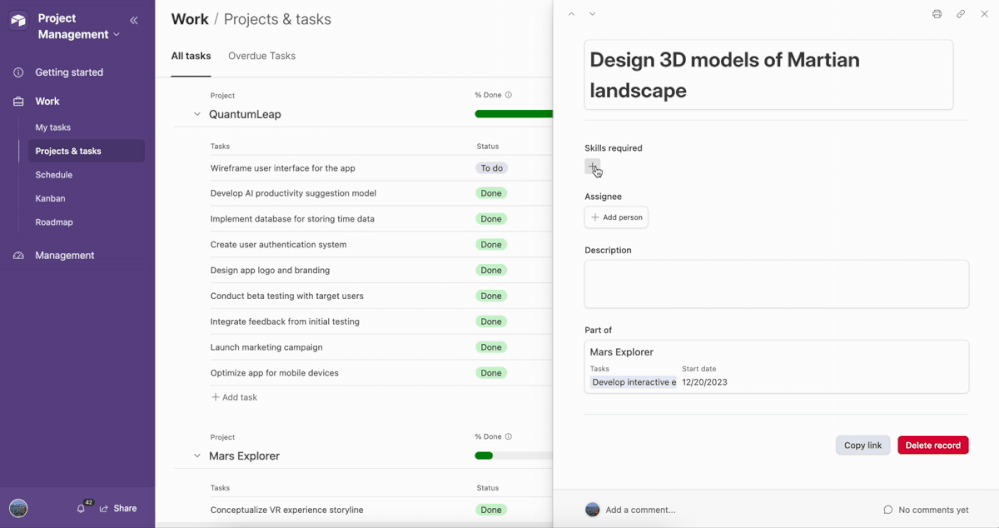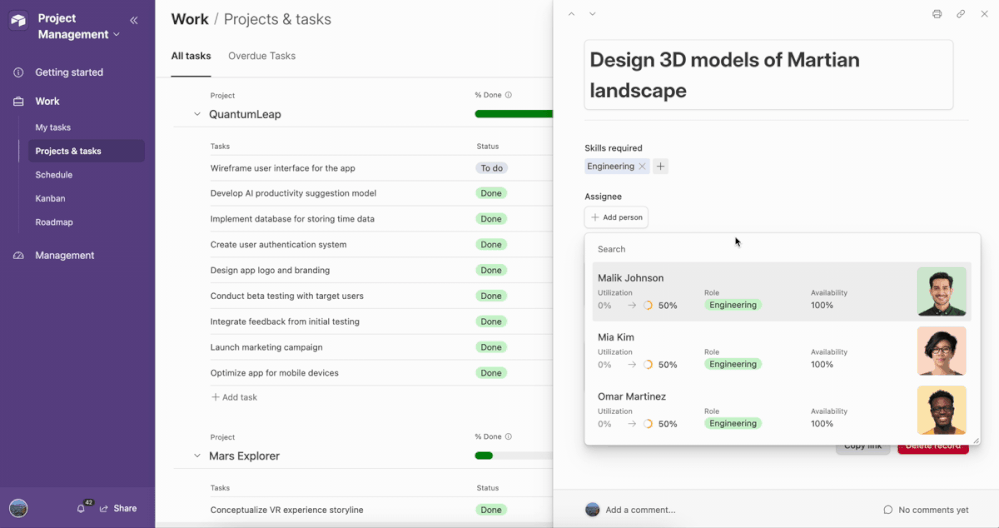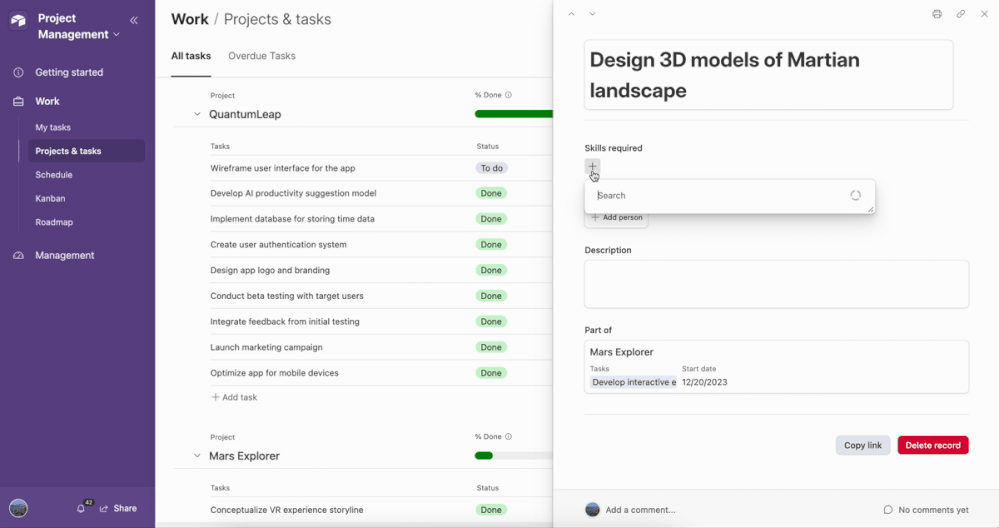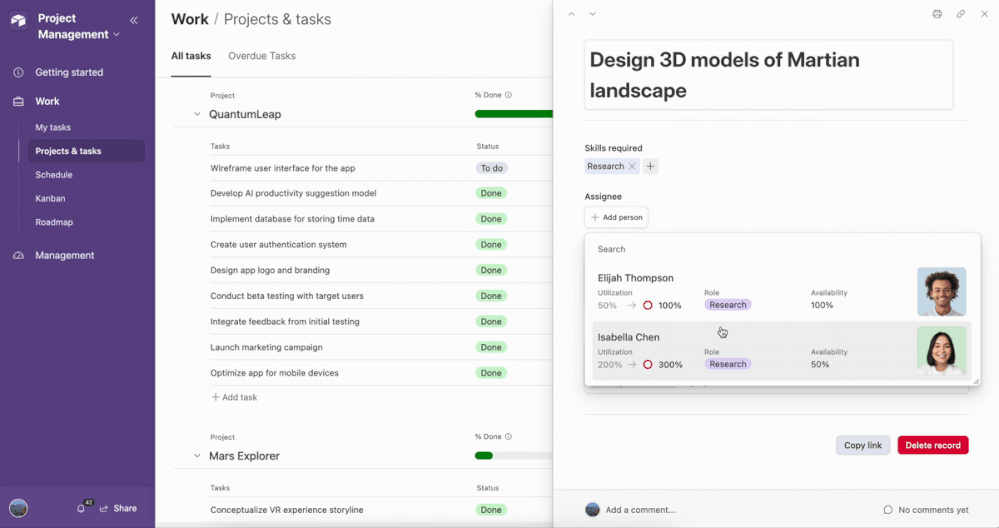
Automation to assign
I would like to create an automation to assign an assignee to the A field in Airtable. The order of assigning a person in charge proceeds in the following order: ‘Lee Ye-ji’ -> ‘Sim Hyo-bin’ and must be repeated continuously.please help me!
- 28 Views
- 0 replies
- 0 kudos