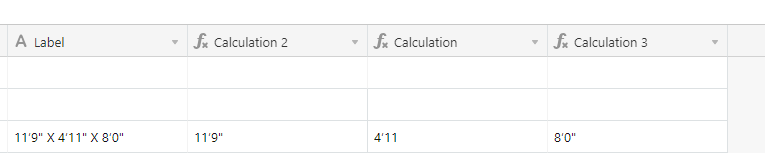
Hello, I am looking to extract the individual dimensions of an object from a cell that contains them as a LXWXH string. for example, I have a cell that looks like 11’9" X 4’11" X 8’0", and would need those in three different cells as 11’9" | 4’11" | 8’0". Trying to find a formula that would do this for me. Thanks!



Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.