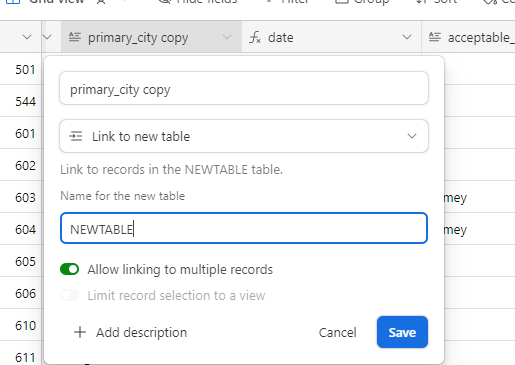
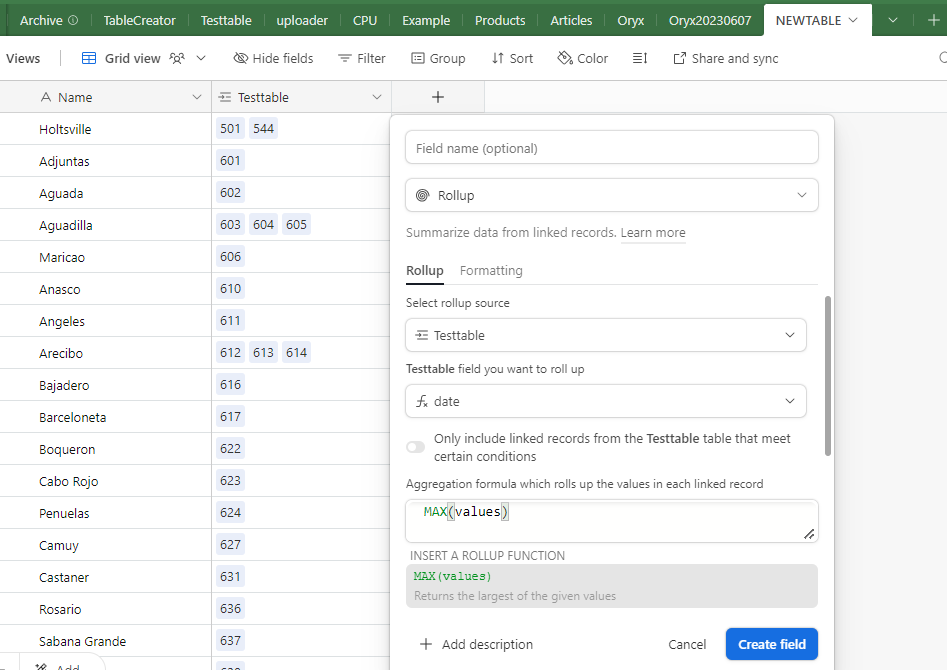
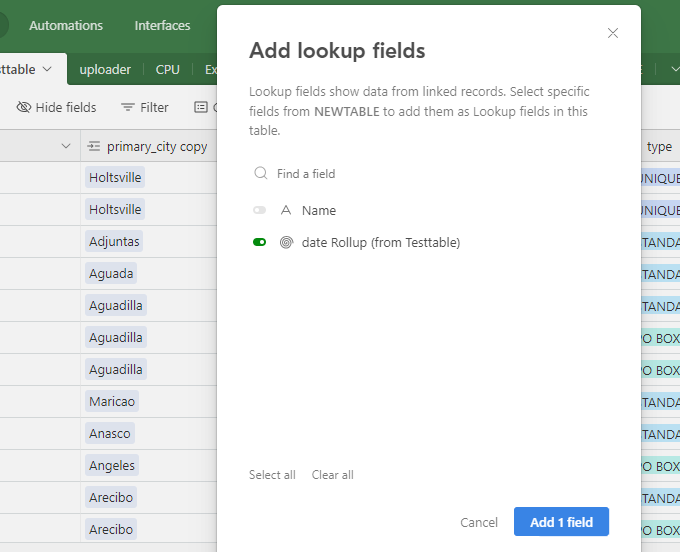
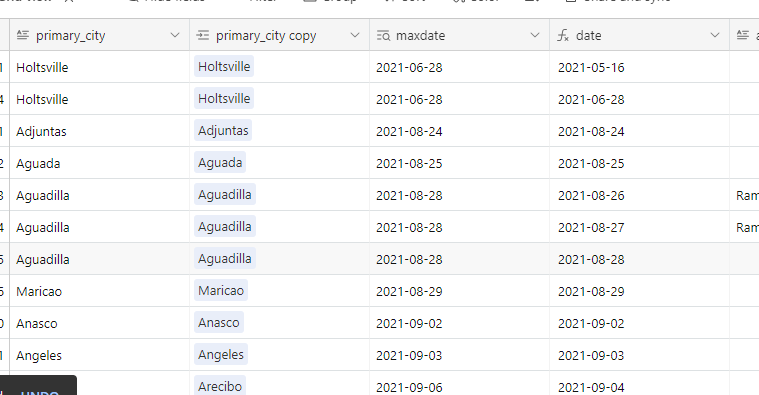
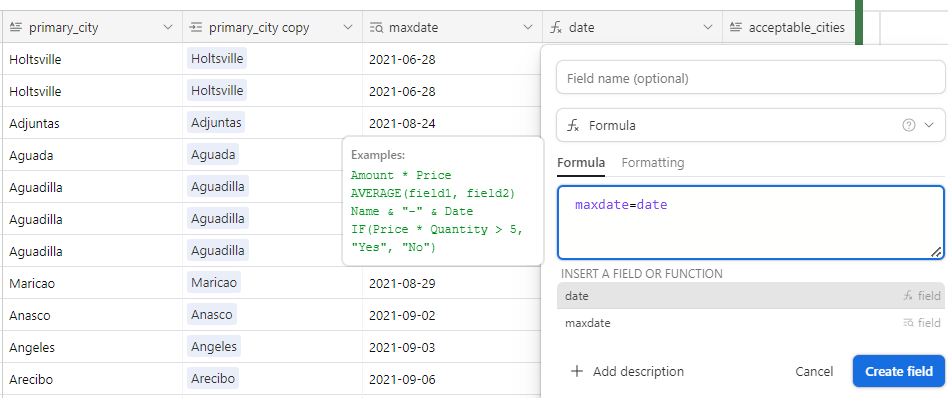
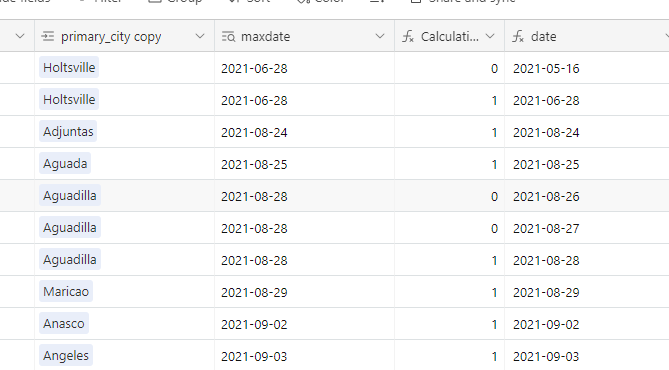
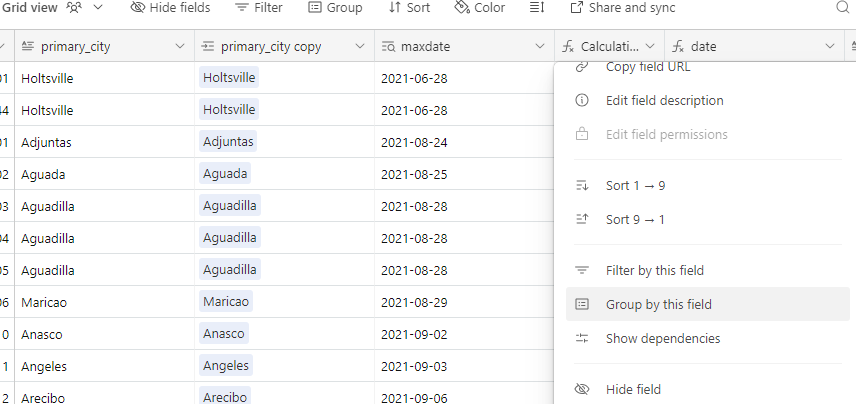
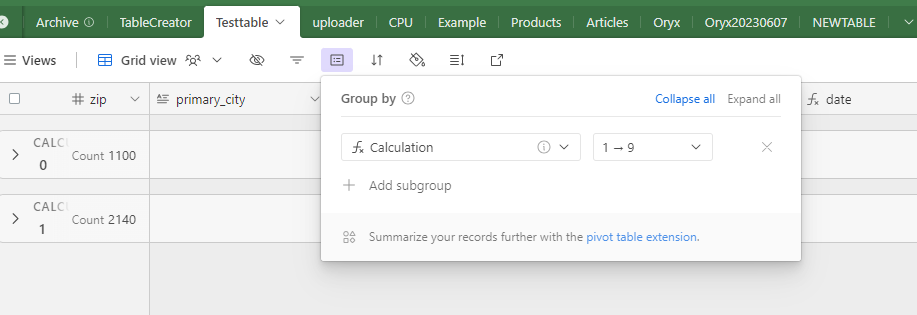
I have an airtable base that contains data from a dozen sources and lots of duplicates. The duplicates are easy to define based on phone number. With dedupe currently you have to look at each individual cluster of duplicates and select what you want to keep. That's fine for some scenarios but that should not be the only option. It would take hours for me to look at each cluster.
There should be a easy way to:
1- Select the fields where duplicates exist.
2- Select which record to keep (most completed fields, newest, oldest, etc).
3- Run it and be done.
I really don't want to have to export to excel and re-import because airtable can't handle such a simple function.