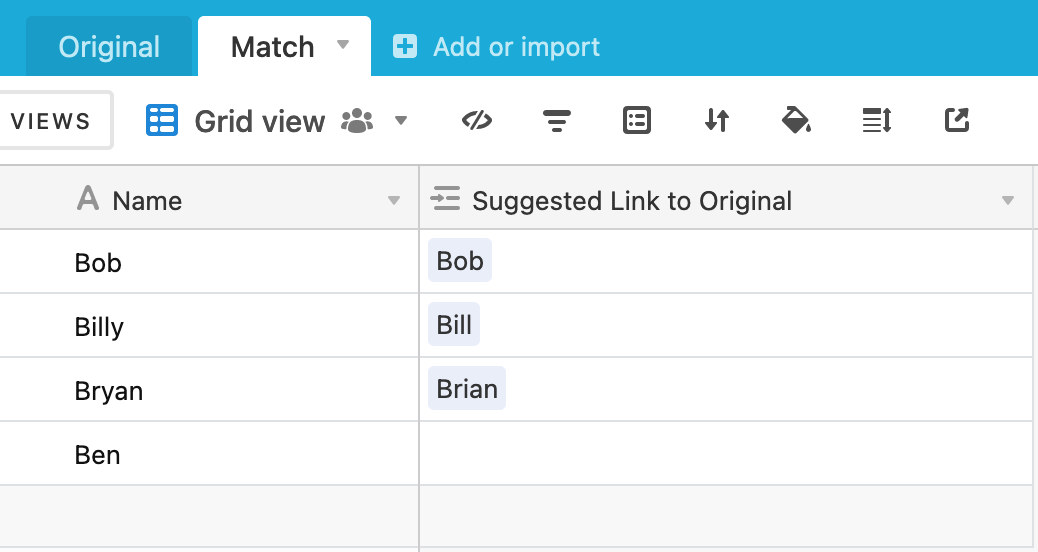
Inspired by this question:
I thought I would try to use Python to do some fuzzy matching on Airtable data. Not really an Airtable demo (as the data could be stored anywhere), but hopefully some readers find this interesting :slightly_smiling_face:
This article:
pointed me to a Python library for fuzzy matching (fuzzywuzzy) and gives some good code snippets for how to use the library.
As per the original post, I used a Donors/Donation base to prototype the matching process. I have a Donors table:
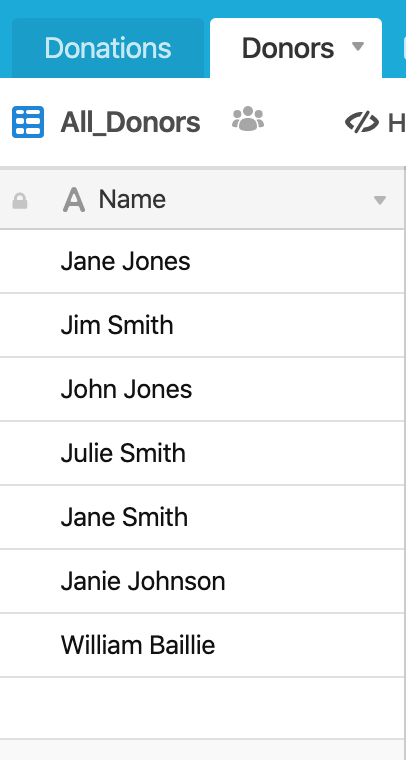
and a Donations table:
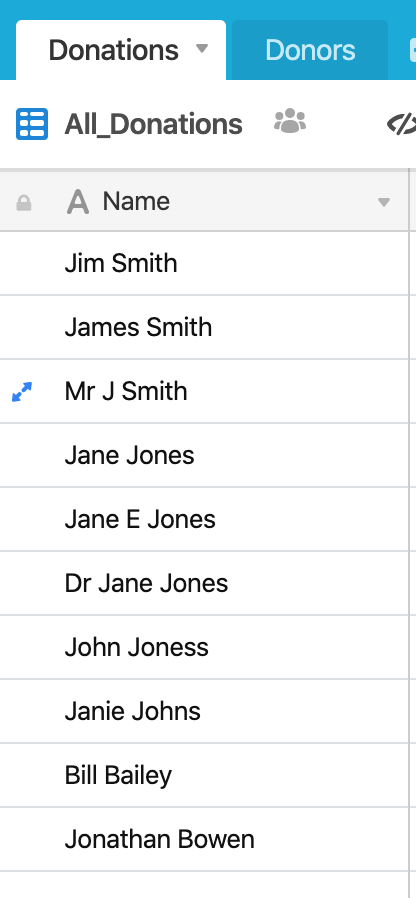
The aim is to use a fuzzy matching routine to suggest which is the closest matching record in the Donor table for each Donation.
I added Suggested Donor and Suggested Donor Score fields to the Donations table:
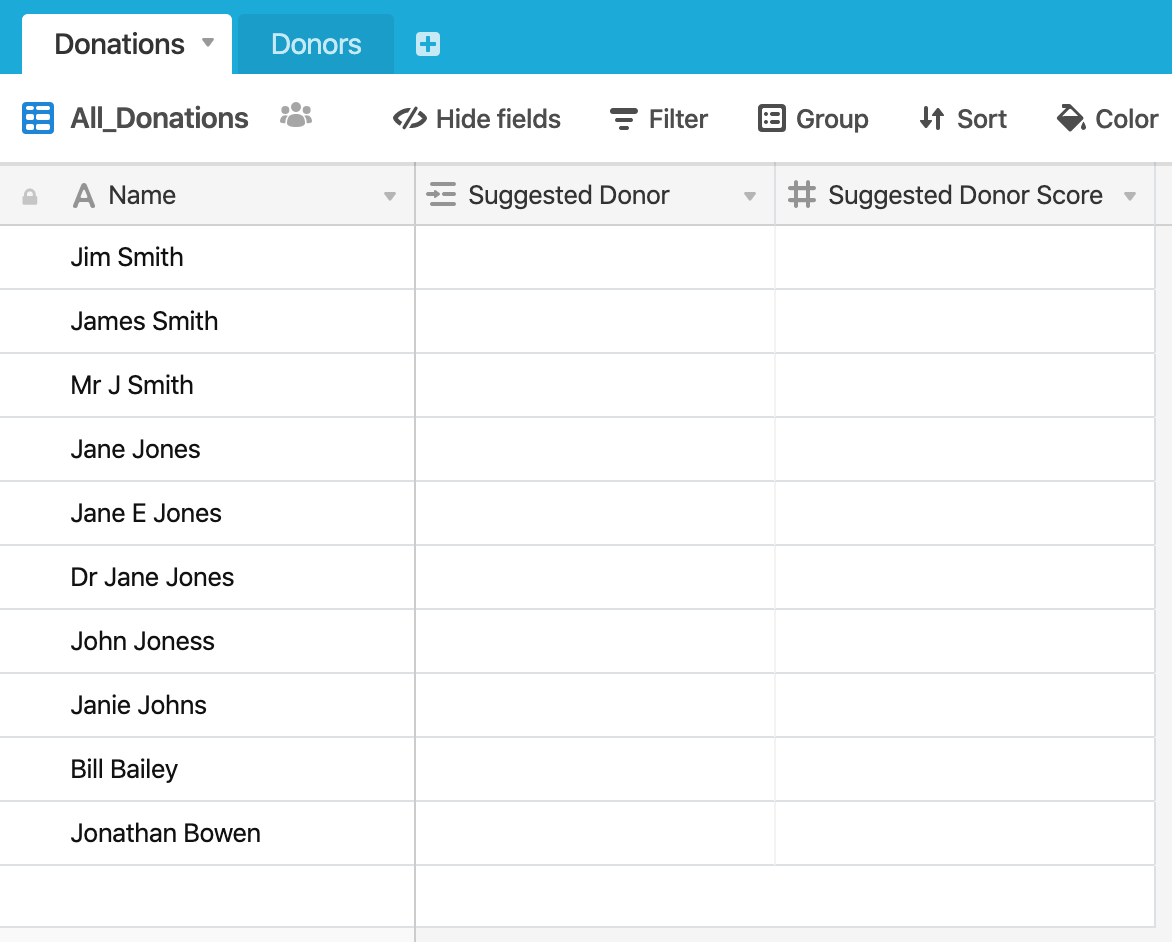
I have a Python script which uses the Airtable API to compare every donation name to every donor name and insert the closest matching, i.e. highest scoring, into the Suggested Donor field. This is set up as a linked record so that, for example, the donation total could be rolled up on the Donors table.
When the script runs you end up with this:
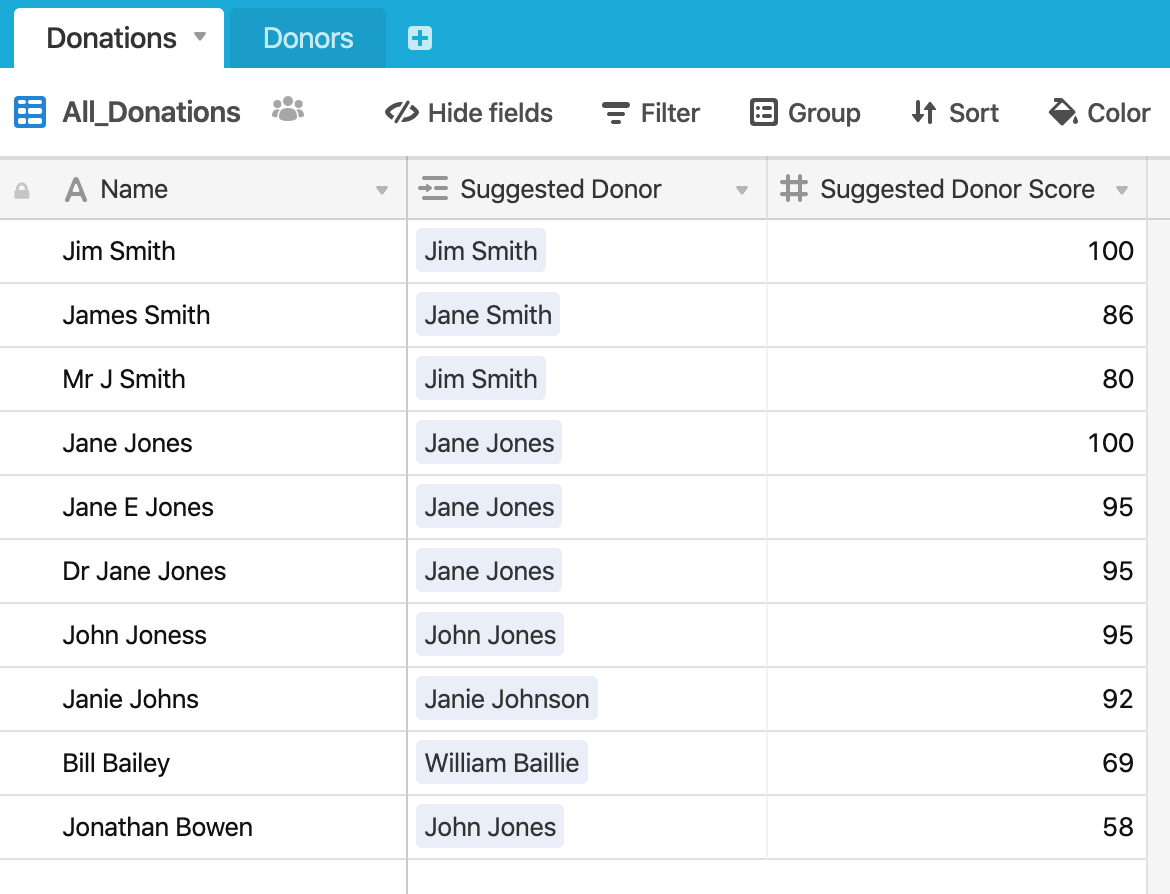
(A score of 100 being an exact match). There’s some low scores (58) which are obviously not a match and some high scores (James Smith/Jane Smith/86) which are also not a match.
Setting the threshold to a high number in the script, e.g. >= 95, gives this:
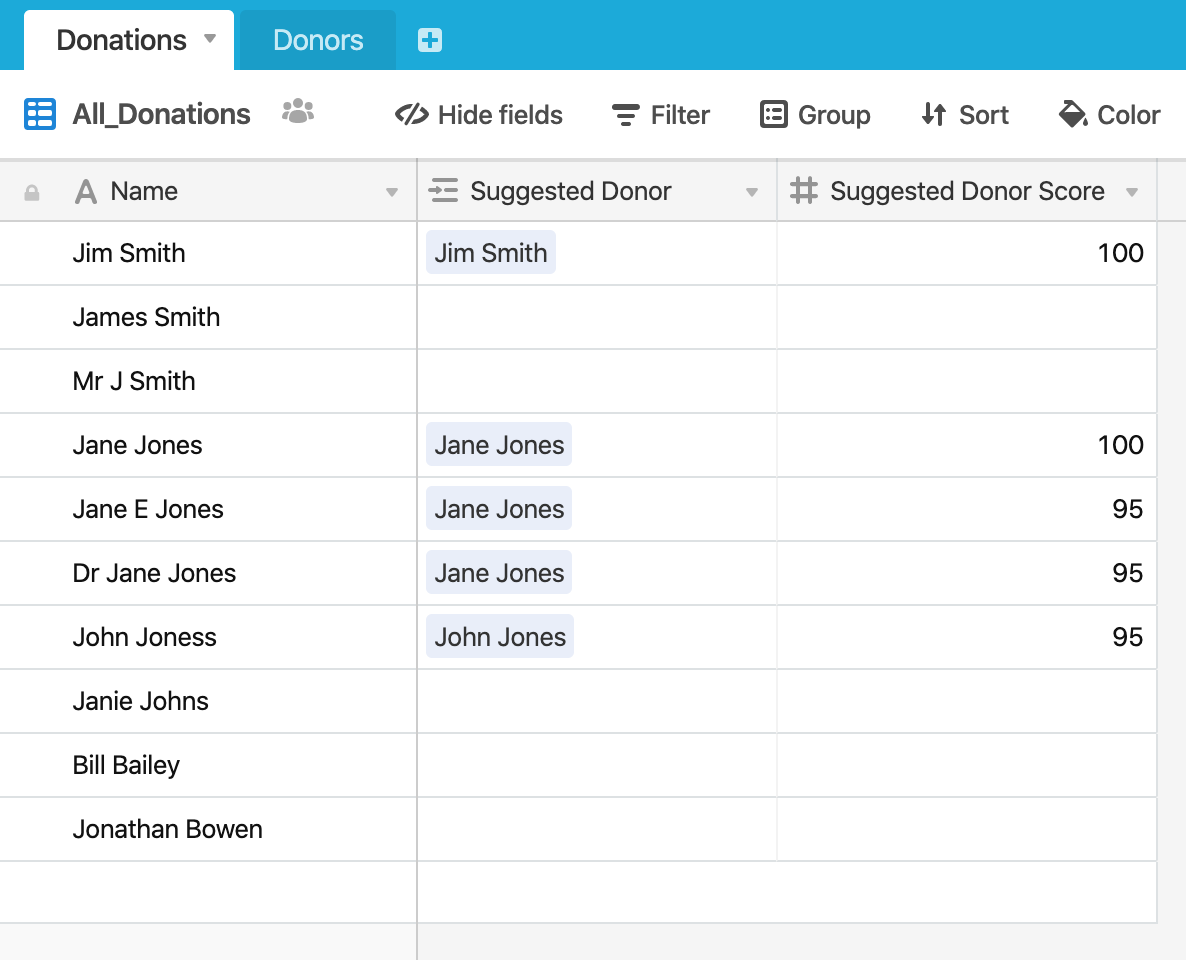
This might be a better approach where a decent proportion of the records are matched, leaving you to match the others manually, but you have high confidence in the records that have been matched.
Here’s the Python script:
import json
import requests
from fuzzywuzzy import process
get_headers = {
'Authorization': 'Bearer YOUR_API_KEY'
}
# get an array of donors
donors_url = 'https://api.airtable.com/v0/YOUR_APP_ID/Donors?maxRecords=100&view=All_Donors'
donors_response = requests.get(donors_url, headers=get_headers)
donors_data = donors_response.json()
donors_list = []
for j in donors_data['records']:
donors_list.append(j['fields']['Name'])
# get the donations
donations_url = 'https://api.airtable.com/v0/YOUR_APP_ID/Donations?maxRecords=100&view=All_Donations'
donations_response = requests.get(donations_url, headers=get_headers)
donations_data = donations_response.json()
# for each donation get the highest matching donor record
for i in donations_data['records']:
donor_name = i['fields']['Name']
highest = process.extractOne(donor_name, donors_list)
# if the highest match has a score >= 80 (or some other score)...
if highest[1] >= 95:
# ...get the donor record...
params = querystring = {"filterByFormula":"({Name}=\\""+highest[0]+"\\")"}
get_matching_donor_response = requests.get(donors_url, headers=get_headers, params=querystring)
matching_donor_id = get_matching_donor_response.json()['records'][0]['id']
# ... and update the donation with the "suggested donor"
update_url = 'https://api.airtable.com/v0/YOUR_APP_ID/Donations/' + i['id']
update_headers = {
'Authorization': 'Bearer YOUR_API_KEY',
'Content-Type': 'application/json'
}
update_data = {
"fields": {
"Suggested Donor": [
matching_donor_id
],
"Suggested Donor Score": highest[1]
}
}
print(update_data)
update_response = requests.patch(update_url, headers=update_headers, json=update_data)
print(update_response.text)
Looking forward to the new Airtable scripting capability (now in private beta?) where I hope we might be able to do similar things wholly within Airtable.
JB