Hello all!
I am working out on building a base for my analytical laboratory. I have say, 5 experiments producing 20 samples a day. Each sample might need to be run on many tools. Let’s say a GCMS, a NMR, FTIR (science stuff)
I am trying to figure out how to best handle this. If this were a simple “create sample”->“run sample”->“Done” scenario, I wouldn’t be posting here, but it is more complex.
I want the machine operator at the GCMS to be able to sit down each day, and see what items are in the to-do list for that tool, and I want that person to be able to mark as in-progress or complete. Same thing for all other operators.
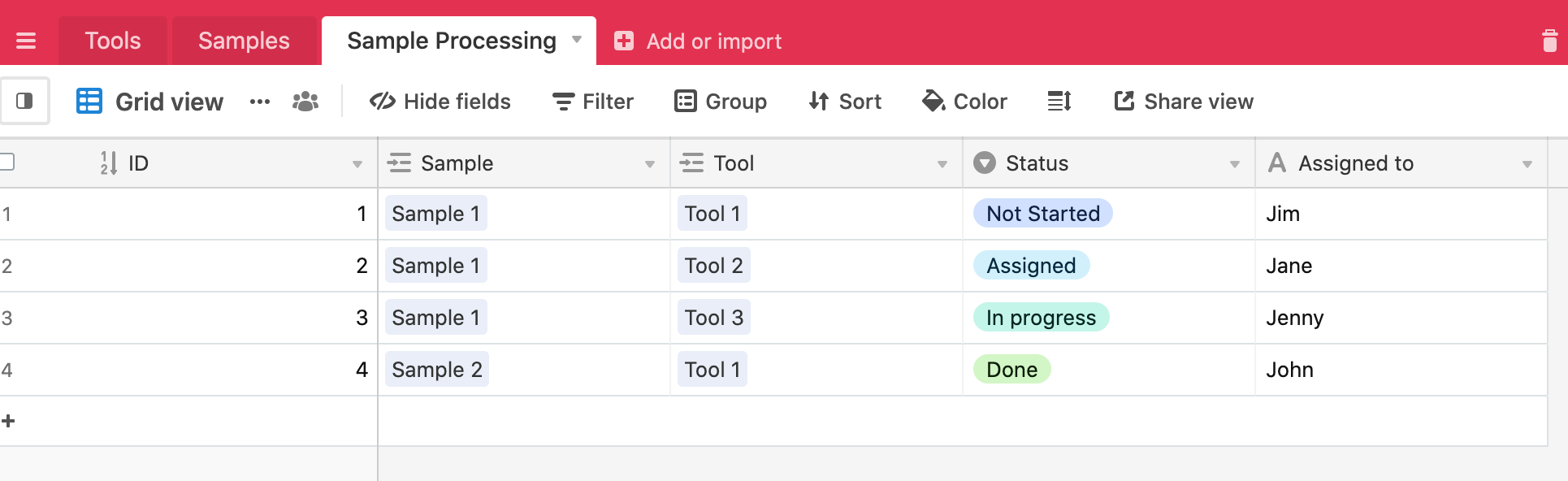
I am using a table for tools, and a table for samples. Each sample has a multilinked record to tools for to-do. Then, there is a multi-linked record for in-process, as well as complete.
This all works, but it can be a bit clunky. The tool operator has to manually delete the “to-do” tool link, then create the “in progress” tool link.
I know I might be overthinking things, but let me restate it in a better way:
Let’s say you had a task-tracking database where the flow from entry creation to completion could go down various paths. Let’s say that you always started with a widget, but some widgets get painted, others get polished, some get shipped off and some go through all of that.
So a simple in-progress flag doesn’t help that much, as it could be in any of those states. And adding an in-progress per each task type seems a bit inelegant to me, because each tool/process would require me to create a new single select field, leaving me with bloated tables full of single select fields.
Also, there would be no traceability, I want the tool records to “own” all the completed samples.
All of this might be solved if they ever let you kanban with linked records rather than single select fields, but even then, it creates problems.
It is a one-to-many and many-to-one problem. Each sample might go through 10 tools, and each tool might digest 1000 samples.