I just read this Contacting Airtable Support about bugs
Says to use the In-App to contact Support.
SO — how do we contact support when we’re getting this
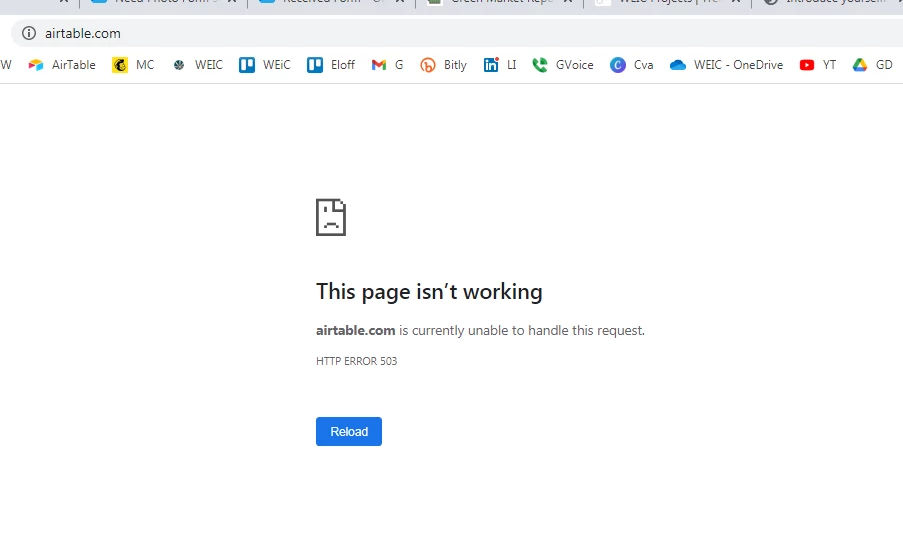

I just read this Contacting Airtable Support about bugs
Says to use the In-App to contact Support.
SO — how do we contact support when we’re getting this
Best answer by Jason11
This incident has been fully resolved. Our apologies again for the disruption, and thank you to everyone for your patience.
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.


