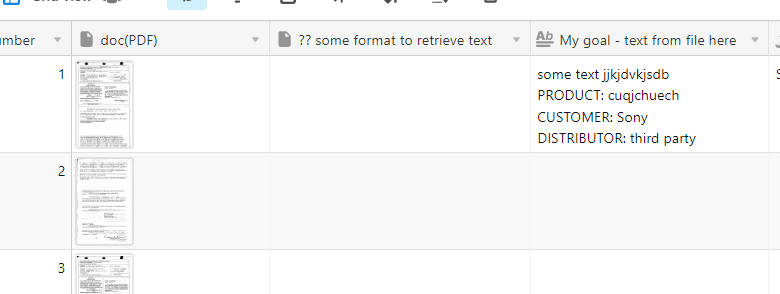
Hi,
I need to extract text from multiple (thousands) of PDF files and load it to Airtable so that I can read that text by AT script, each portion of text for each file.
Files are stored locally, and I wrote an uploader, which can, for example, for each loaded 200 files (file1, file2 etc…) create new table with 1 record per file.
I can use bulk conversion by Acrobat (to doc, html or txt format) and upload those files in the same way. The question is - what format could be used to retrieve the text by AT script?
For now I see that I need to write some node.js script (with pdfjs) that will retrieve the text, or remix some AT extension using API to upload text. Can it be done with less efforts?
I didn’t consider, at least for now, using 3rd party tool subscriptions because I cannot tell for now how often it be used. maybe one time, maybe more and more, with the total of files up to hundred of thousands.
Note: files are already OCR-processed and they are editable PDFs. Maybe a file can be loaded as binary and text is somehow extracted from it?
It’s ok for me to perform bulk conversion and upload in manual mode
To make question more clear:
And here is the question - what format can be used to retrieve text by script, running it per record
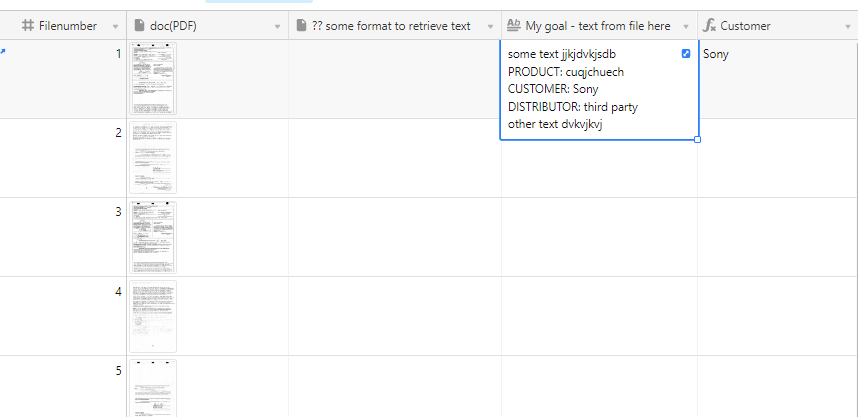
I don’t care much about text formatting, 'cause I will use it to extract values
All files are small, 1-2pages.