Hello all,
Wondering if anybody can suggest efficient way to extract text and put into fields.
I was going to play with LEN and SUBSTITUTE formulas but I know it will take me a day or two to figure it out because I don’t really understand well how the two formulas work. I have used them successfully to extract Airtable attachment links to separate fields as URLs and it only worked because some genius here came with the suggestion.
All I try to do is to go to Amazon, copy the description, I would past that into a field and then the formulas would grab it and populate the individual fields.
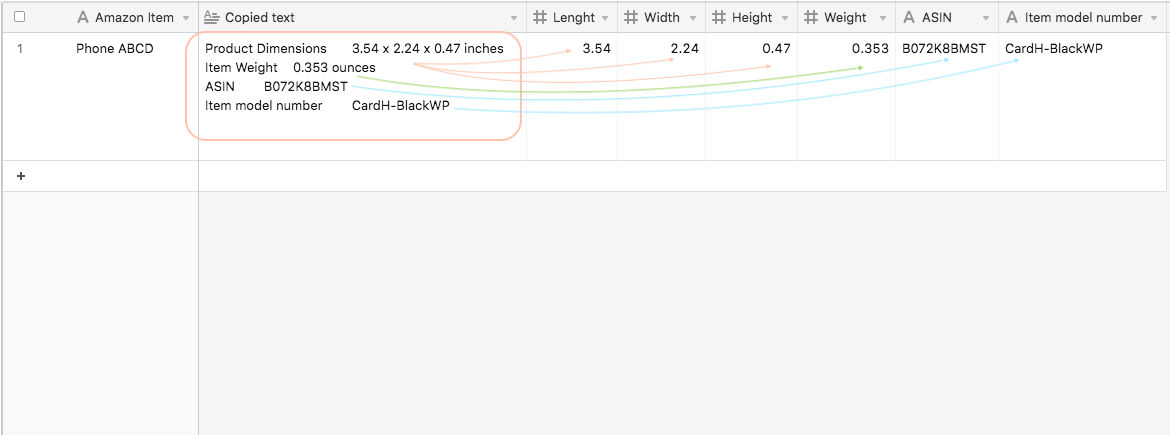
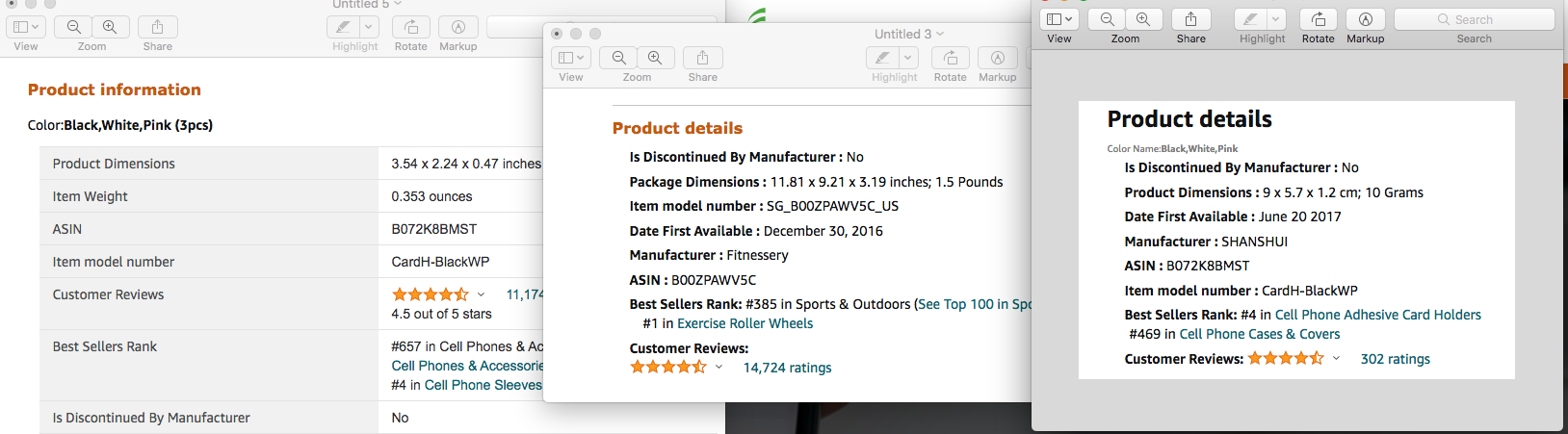
Specifically I am grabbing this information (PRODUCT INFORMATION - it’s at the end of description in Amazon product page, just before the Customer Questions & Answers section).
This is what I need to copy:
| Product Dimensions | 3.54 x 2.24 x 0.47 inches |
|---|---|
| Item Weight | 0.353 ounces |
| ASIN | B072K8BMST |
| Item model number | CardH-BlackWP |
====
The formatting doesn’t show up when past in Airtable. The text contains some vertical lines | when I copy them from Amazon which I believe can be helpful to build the formula.
However, when I past the text to Airtable, the vertical lines don’t show up, so I guess they are just “gaps” and not really vertical lines.
So I guess it’s just requires a lot of testing to get it work but before I even try to go with the two formulas, I am wondering if there is any other better way doing it.
Many thanks.