
hi i have a column with codes like this “0010o00002Fs719AAB”
What will the formula to extract the 8 of the code?
it should become Fs719AAB.
Thanks in advance!
Chris
 +2
+2hi i have a column with codes like this “0010o00002Fs719AAB”
What will the formula to extract the 8 of the code?
it should become Fs719AAB.
Thanks in advance!
Chris
+2RIGHT({Field name}, 8)
More formula reference:
Thanks so much! worked like a charm
Hi,
I have three examples below. What code required to extract just the dollar amount for all three examples?
WEEKLY PAY 9888.95 N
FULL TANK-FUEL -80.00 N
T8IPK68700 300.00 N
Thanks!
 +21
+21Hi,
I have three examples below. What code required to extract just the dollar amount for all three examples?
WEEKLY PAY 9888.95 N
FULL TANK-FUEL -80.00 N
T8IPK68700 300.00 N
Thanks!
I can’t think of a way to extract that number because there are too many inconsistencies in the formatting.
There may be a way to do it by running a bunch of nested tests to check for various combinations of separating spaces, but IMO it would be more of a headache than it’s worth.
I knew it would be a challenge, thanks for your help!
+21I knew it would be a challenge, thanks for your help!
Okay, I don’t know what it is lately, but the past two days I’ve woken up with solutions to certain problems in my head, and today it was this one. I recalled a trick I’d seen elsewhere, and it works quite well in this case. Here’s the formula to extract that value. {Text} is my field where I put the source text; change it to match your own field name:
VALUE(TRIM(RIGHT(SUBSTITUTE(SUBSTITUTE(Text, " N", ""), " ", REPT(" ", 10)), 12)))
At first it might look like the decimals are being ignored, but they’re not. That’s just formatting. Format the field as currency ,or decimal with two places, and you’ll see them.
Justin,
You are an Airtable Jedi! The force are with you, it works!
Hi Justin,
How would you re-write the code so that it will works my other text lines that ending with A, S or something else? I have all these in the same field.

+21Hi Justin,
How would you re-write the code so that it will works my other text lines that ending with A, S or something else? I have all these in the same field.
This should work, as long as the amount to trim off the right end is always two characters (i.e. a space and a single letter).
VALUE(TRIM(RIGHT(SUBSTITUTE(LEFT(Text, LEN(Text) - 2), " ", REPT(" ", 10)), 12)))Hi Justin,
I’ve tried your revised formula but got an error message. What’s missing?
VALUE(TRIM(RIGHT(SUBSTITUTE(LEFT(Expenses Accounts, LEN(Expenses Accounts) - 2), " “, REPT(” ", 10)), 12)))
+21Hi Justin,
I’ve tried your revised formula but got an error message. What’s missing?
VALUE(TRIM(RIGHT(SUBSTITUTE(LEFT(Expenses Accounts, LEN(Expenses Accounts) - 2), " “, REPT(” ", 10)), 12)))
When a field name contains spaces, it must be wrapped in curly braces (like how that rhymes?) :winking_face: Also, double-check your quotes (unless they just got curled by posting here).
VALUE(TRIM(RIGHT(SUBSTITUTE(LEFT({Expenses Accounts}, LEN({Expenses Accounts}) - 2), " ", REPT(" ", 10)), 12)))
FWIW, to force the forum parser to format text as pre-formatted text, indent single lines with four spaces (as above). For blocks of code, type a triplet of inverted apostrophe characters ( ` ) on their own lines both before and after. The text in this screenshot:

…becomes this when formatted…
This text is pre-formatted.
Some text becomes automatically color-coded this way, like "strings".
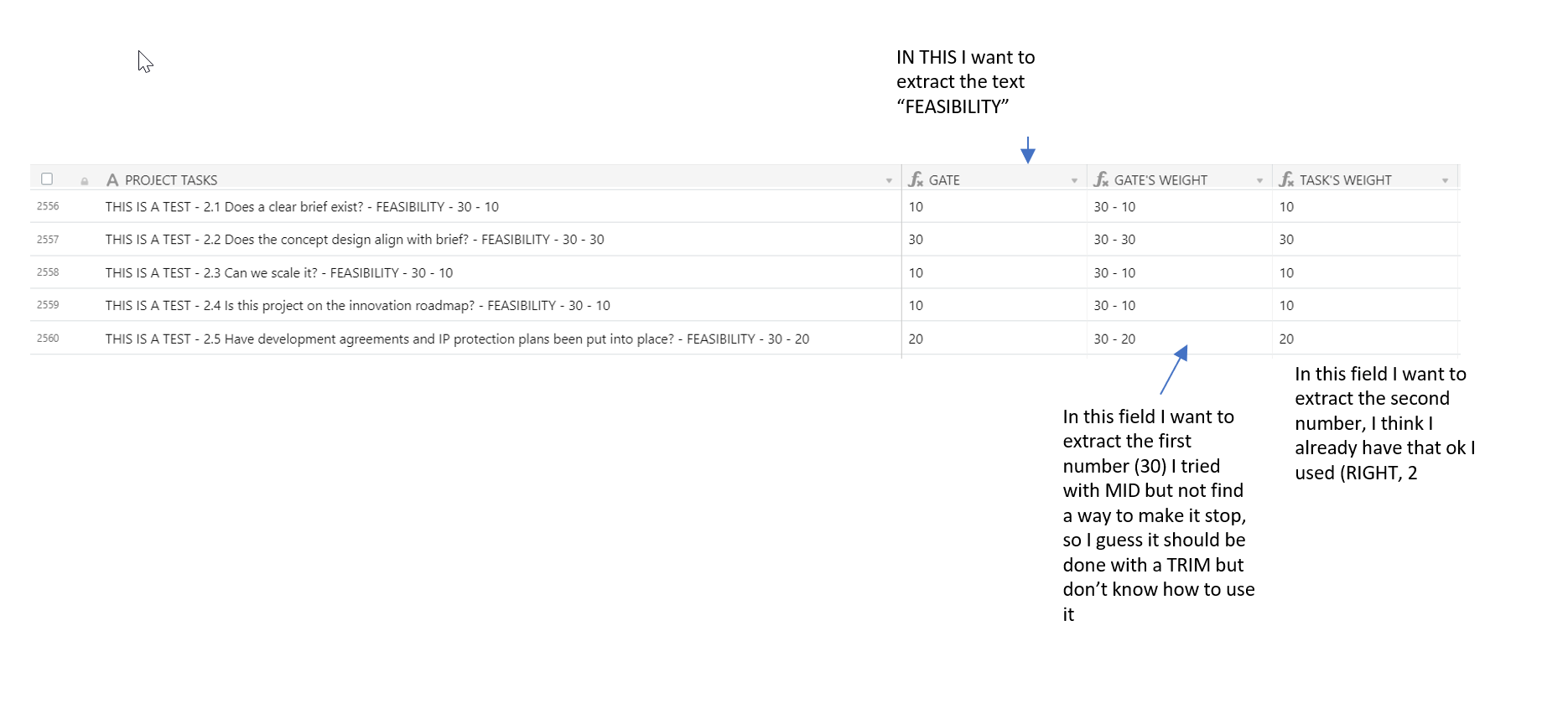
Hello, I would like some help to use trim, please see the image, thanks!
+21
Hello, I would like some help to use trim, please see the image, thanks!
Welcome to the community, @Laura_Flores! :grinning_face_with_big_eyes: I’m guessing you’re going for a more general approach—some records might have a different word (or series of words) in place of “FEASIBILITY”, different numbers, etc.—so I built my solution to not look for too many specific features in the text. The only things I’m counting on being consistent are the separators (" - "), and each task name/label ending in a question mark.
To solve this, I actually found it easier to work backwards. As you found, pulling {TASK'S WEIGHT} off the end with RIGHT() is easy. From there, I used that extraction to aid in pulling off the number before it for {GATE'S WEIGHT}, and the combination of those two to extract the text for {GATE} (“FEASIBILITY”, or whatever text may be after the question but before the first number). And I didn’t need to use TRIM(). :slightly_smiling_face: Here are my test results:

And here are the formulas. First for {GATE}:
MID(SUBSTITUTE({PROJECT TASKS}, " - " & {GATE'S WEIGHT} & " - " & {TASK'S WEIGHT}, ""), FIND("? - ", {PROJECT TASKS}) + 4, 50)
Next for {GATE'S WEIGHT}:
IF({PROJECT TASKS}, VALUE(RIGHT(SUBSTITUTE(SUBSTITUTE({PROJECT TASKS}, " - ", "|"), "|" & {TASK'S WEIGHT}, ""), 2)))
And finally {TASK'S WEIGHT}:
IF({PROJECT TASKS}, VALUE(RIGHT({PROJECT TASKS}, 2)))
Notice that I wrapped the numerical extractions in VALUE() to turn them into numbers, in case you want to use those in any other formula calculations.
Welcome to the community, @Laura_Flores! :grinning_face_with_big_eyes: I’m guessing you’re going for a more general approach—some records might have a different word (or series of words) in place of “FEASIBILITY”, different numbers, etc.—so I built my solution to not look for too many specific features in the text. The only things I’m counting on being consistent are the separators (" - "), and each task name/label ending in a question mark.
To solve this, I actually found it easier to work backwards. As you found, pulling {TASK'S WEIGHT} off the end with RIGHT() is easy. From there, I used that extraction to aid in pulling off the number before it for {GATE'S WEIGHT}, and the combination of those two to extract the text for {GATE} (“FEASIBILITY”, or whatever text may be after the question but before the first number). And I didn’t need to use TRIM(). :slightly_smiling_face: Here are my test results:
And here are the formulas. First for {GATE}:
MID(SUBSTITUTE({PROJECT TASKS}, " - " & {GATE'S WEIGHT} & " - " & {TASK'S WEIGHT}, ""), FIND("? - ", {PROJECT TASKS}) + 4, 50)
Next for {GATE'S WEIGHT}:
IF({PROJECT TASKS}, VALUE(RIGHT(SUBSTITUTE(SUBSTITUTE({PROJECT TASKS}, " - ", "|"), "|" & {TASK'S WEIGHT}, ""), 2)))
And finally {TASK'S WEIGHT}:
IF({PROJECT TASKS}, VALUE(RIGHT({PROJECT TASKS}, 2)))
Notice that I wrapped the numerical extractions in VALUE() to turn them into numbers, in case you want to use those in any other formula calculations.
Thanks so much Justin!! I appreciate your help!
 +1
+1Justin,
You are an Airtable Jedi! The force are with you, it works!
I agree 100% and I only saw this one solution, where he like woke up and had it. That’s like Jedi Mind trick stuff.
Okay, I don’t know what it is lately, but the past two days I’ve woken up with solutions to certain problems in my head, and today it was this one. I recalled a trick I’d seen elsewhere, and it works quite well in this case. Here’s the formula to extract that value. {Text} is my field where I put the source text; change it to match your own field name:
VALUE(TRIM(RIGHT(SUBSTITUTE(SUBSTITUTE(Text, " N", ""), " ", REPT(" ", 10)), 12)))
At first it might look like the decimals are being ignored, but they’re not. That’s just formatting. Format the field as currency ,or decimal with two places, and you’ll see them.
Clever! This just saved me a lot of headache :thumbs_up: I can’t count how many of your posts have helped me, thank you so much for your time here!
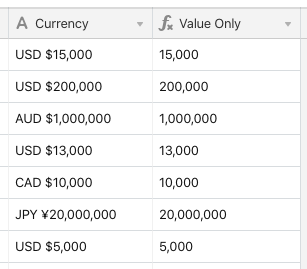
@Justin_Barrett I’m hoping your exceptional skills in this department can help me as well. I am trying to create a formula to automatically pull the value out of a series of currencies and I keep getting an ERROR message, so I’m clearly doing something wrong. The problem is there are several different currencies and value lengths.
Is there a formula I can use to only show the numerical value (including commas) for entries similar to these? I only want the numbers (example: 15,000 and 200,000 - no text or currency symbol)
USD $15,000
USD $200,000
AUD $1,000,000
USD $13,000
CAD $10,000
JPY ¥20,000,000
USD $5,000
Thank you very much in advance!!
+21@Justin_Barrett I’m hoping your exceptional skills in this department can help me as well. I am trying to create a formula to automatically pull the value out of a series of currencies and I keep getting an ERROR message, so I’m clearly doing something wrong. The problem is there are several different currencies and value lengths.
Is there a formula I can use to only show the numerical value (including commas) for entries similar to these? I only want the numbers (example: 15,000 and 200,000 - no text or currency symbol)
USD $15,000
USD $200,000
AUD $1,000,000
USD $13,000
CAD $10,000
JPY ¥20,000,000
USD $5,000
Thank you very much in advance!!
@Louise_Nightingale Regex to the re(gex)scue! :winking_face:
IF(Currency, REGEX_EXTRACT(Currency, "[\\d,]+"))
Breakdown…
\d token matches any digit (the extra backslash is required to escape the backslash needed by the token), and the comma matches a literal comma+ at the end tells the interpreter to make that previous match one or more times@Louise_Nightingale Regex to the re(gex)scue! :winking_face:
IF(Currency, REGEX_EXTRACT(Currency, "[\\d,]+"))
Breakdown…
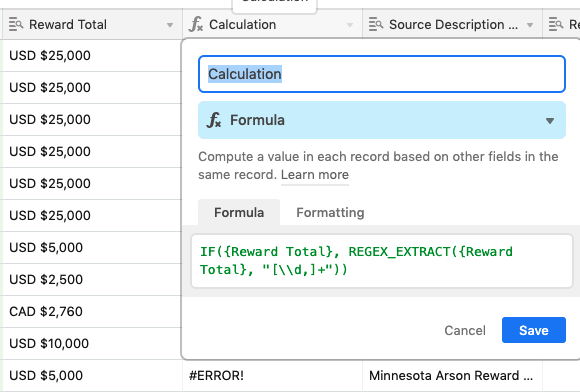
\d token matches any digit (the extra backslash is required to escape the backslash needed by the token), and the comma matches a literal comma+ at the end tells the interpreter to make that previous match one or more timesThank you for the swift response, @Justin_Barrett - I’m sadly getting that same pesky #ERROR! message.
I didn’t mention that the currency data I’m trying to pull from is a lookup result from another tab. Does that matter?
I’ve attached a screen shot in case it’s useful
+21Thank you for the swift response, @Justin_Barrett - I’m sadly getting that same pesky #ERROR! message.
I didn’t mention that the currency data I’m trying to pull from is a lookup result from another tab. Does that matter?
I’ve attached a screen shot in case it’s useful
Yes. Lookup fields return arrays, not single values, and Airtable’s regular expression functions only operate on strings. This can be fixed by concatenating the lookup field output with an empty string, which force-converts it to a string.
IF({Reward Total}, REGEX_EXTRACT({Reward Total} & "", "[\\d,]+"))
When a lookup field is only pulling from a single linked record (as in your situation), it still returns an array, but there are limited instances where Airtable will auto-convert that array to a single data type. It’s tough to keep track of all of the options, so I ran a lot of tests and documented my findings here:
I’m also working on a course all about Airtable formulas. It’s not going to be ready for another month or two, but my rough edit currently runs over an hour. If learning the ins and outs of Airtable’s formula system is something that interests you, keep an eye out for when the course is released.
Yes. Lookup fields return arrays, not single values, and Airtable’s regular expression functions only operate on strings. This can be fixed by concatenating the lookup field output with an empty string, which force-converts it to a string.
IF({Reward Total}, REGEX_EXTRACT({Reward Total} & "", "[\\d,]+"))
When a lookup field is only pulling from a single linked record (as in your situation), it still returns an array, but there are limited instances where Airtable will auto-convert that array to a single data type. It’s tough to keep track of all of the options, so I ran a lot of tests and documented my findings here:
I’m also working on a course all about Airtable formulas. It’s not going to be ready for another month or two, but my rough edit currently runs over an hour. If learning the ins and outs of Airtable’s formula system is something that interests you, keep an eye out for when the course is released.
Thanks @Justin_Barrett - late response from me but appreciate your help!
Would love to join your formula course once it’s available!
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.
Sorry, we're still checking this file's contents to make sure it's safe to download. Please try again in a few minutes.
OKSorry, our virus scanner detected that this file isn't safe to download.
OK
