- Airtable Community
- Discussions
- Ask A Question
- Other questions
- Re: Creating master list of tables
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Re: Creating master list of tables
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Mar 29, 2023 11:44 AM
We are using Airtable to inventory and create our perfume formulas. We have one Base for the Working Formulas. We would like to create a table that automatically creates a record whenever a new table is created in the base. This way we will be able to track its progress, etc. Is that doable or should we just create the records manually?
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Mar 29, 2023 01:38 PM
Interesting.
To hop straight to the point: it's possible to do this using the Web API. I've done this before, but in a very specific context. I built a microservice that, when combined with a webhook, received a webhook anytime there was a schema change to the base's structure, specifically tables.
From there, the microservice would create a new record in a base for the newly created table(s).
A possible permutation would be to trigger an automation on a 15/30/45/60 minute interval that would run a script that would query the Web API's base schema endpoint and evaluate whether any tables have been created or deleted before finishing by creating or updating records as necessary to reflect the current schema.
That's an enterprise level solution and is completely overkill and I would actually dissuade most people from implementing a solution like that.
With that being said, I'd like to get a bit of clarity here.
From what you're describing, it seems like you're predicting that you're going to be working with a rather large number of tables. More specifically, from what I gather, you will be frequently creating new tables for your data. That throws a red flag for me.
Based on what you're describing, you're creating new tables for each individual fragrance, and for each fragrance, you're creating new records for each formulation of that fragrance.
You have the right idea, but you've "zoomed" out a bit too far and are on track to end up with an overwhelming number of tables which will inevitably result in a loss of interest in using your solution.
If what I've taken away from your use case is correct, then you really only need is something like three tables.




Food for thought. This approach will allow you to manage a massive number of records without having to worry about sweeping changes to your schema or handling a ridiculous number of tables.
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Mar 29, 2023 02:10 PM
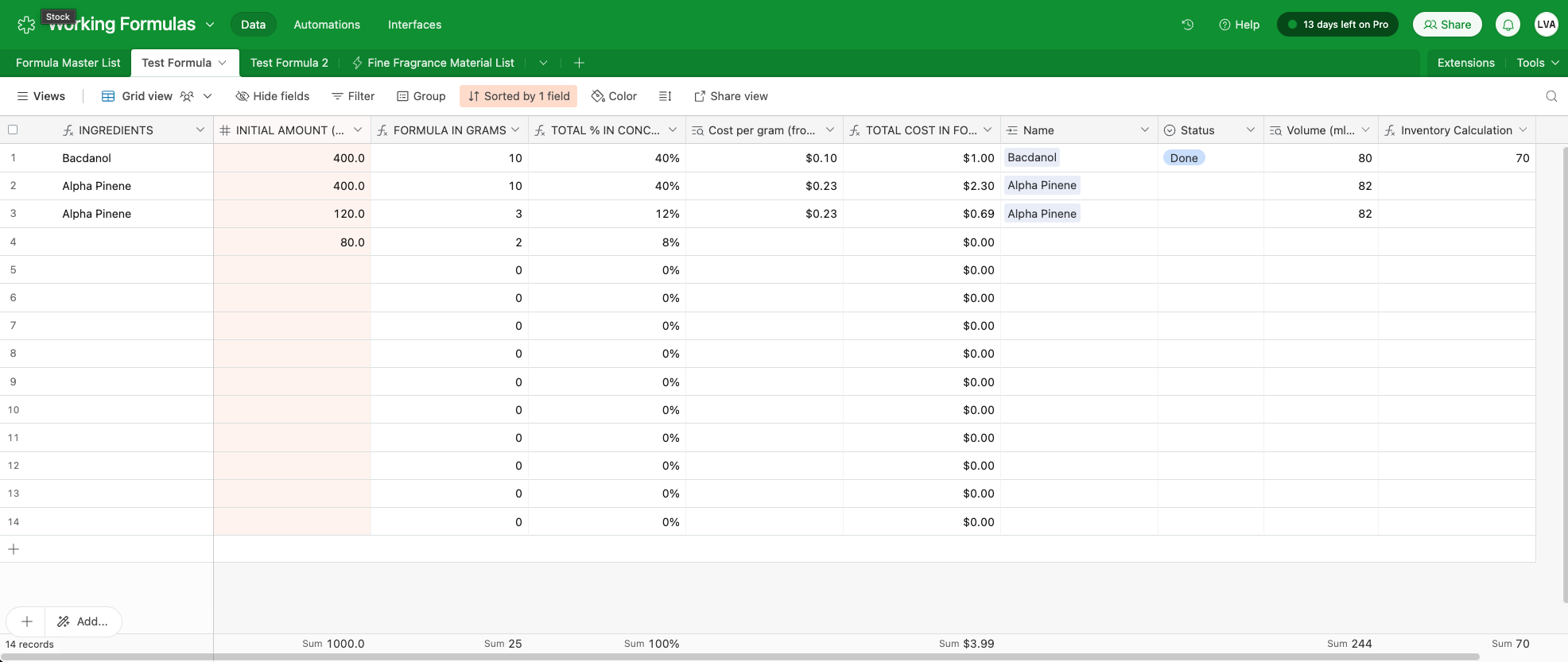
This is a great response. Thanks for taking the time. We went with making a new table for each formula (experiment) because each one needed a certain amount of calculation. This is how we did it in spreadsheets (one per experiment), but this may not be how to do this in a base.
We can't figure out how to get the Formula in Grams part by doing it in one field per experiment. I'm attaching a screen pic to illustrate.
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Mar 30, 2023 08:57 PM - edited Apr 07, 2023 09:00 AM
Here's a link to the base. Feel free to duplicate it, play with it, or whatever else you might please.
Since you need to keep track of unique amounts of a particular material for a given formula, you need a junction record.
For lack of a better object name off the top of my head, I'll create a new table called Components. Each component represents a unique amount of a particular material for a specific formula.
People tend to recoil when you show them a grid view of junction tables, so we'll start with a list view instead. Here's a look at the first layer, where we have each product.

From here, each product may have multiple formulas. Some might be rejected, in testing, or approved:

Finally, we have our components:

As you can see, each component allows you define the quantity of the material for that particular formula.
To do this, we just add the cost per gram of each material to a new field on the material record. This is perfect and is inline with best practices since we know that the cost per gram of a material is something that is supposed to live with the material.

Next we just create a quick rollup on the components table that will return the cost per gram times the quantity:


From there, all we need to do is create a rollup on the formula table that returns the sum of the total material costs

{kind=link}
{kind=link}
When you start working in a data structure like this, I would highly recommend that you either stick to a list view driven workflow or an Interface-based workflow.
When users first work with a database structure that fully embraces a relational database-first mindset and see it from a grid-based perspective, they tend to become extremely overwhelmed, so while I'm always a Interface advocate, I highly recommend it for this workflow.
