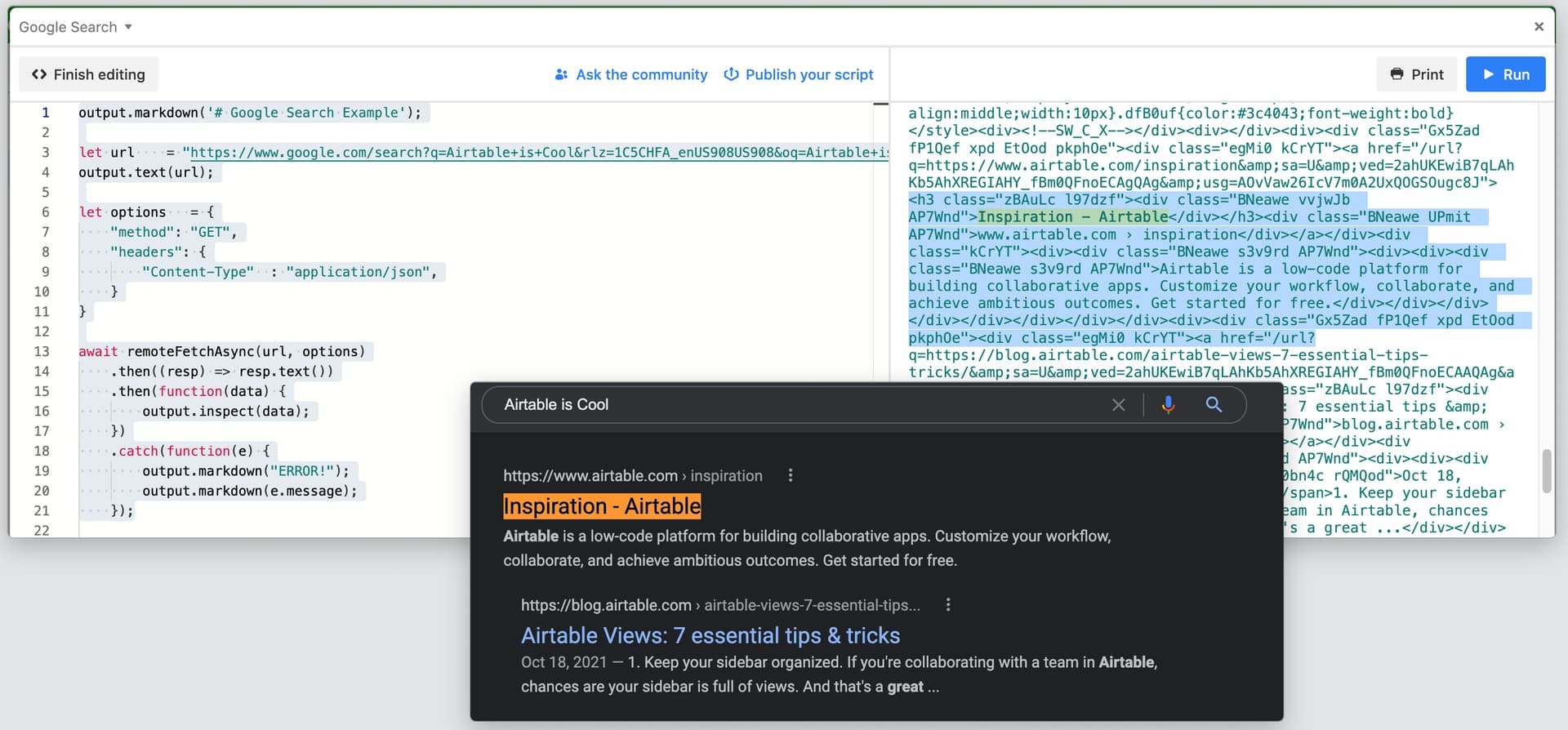
I want to run some code on within Airtable to run a NodeJS script that will scrape Google search results and then save the results to my base.
This is the code: Google API | ScrapingBee
Possible?

I want to run some code on within Airtable to run a NodeJS script that will scrape Google search results and then save the results to my base.
This is the code: Google API | ScrapingBee
Possible?
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.