
what formula can I run against a text field that will display all text characters up to a “,”.
Example: TEXT1, TEXT2
Result: TEXT1
 +4
+4what formula can I run against a text field that will display all text characters up to a “,”.
Example: TEXT1, TEXT2
Result: TEXT1
Best answer by ARTHUR_BENNETT
How do I reformat this ?
Ashbaugh, Cally
to
Cally Ashbaugh
+4How do I extract the third item in an array?
Example: One, Two, Third Item, Four, Five
Result: Third Item
 +21
+21How do I extract the third item in an array?
Example: One, Two, Third Item, Four, Five
Result: Third Item
@Frank_Reagan If it’s a literal array, you’ll first need to convert it to a string. Array indexing isn’t currently possible using formulas. The easiest way to convert an array to a string is with the ARRAYJOIN() function:
ARRAYJOIN(array, ",")
Assuming you’ve got a string, there are at least three items in that string, and there are commas separating each item (as in your example), then this would work:
IF(String, REGEX_EXTRACT(String, "(?:[^,]*, *){2}([^,]*)(?:.*)"))
Your sample also has a space after each comma; this formula will also take that into account in case your data may include that.
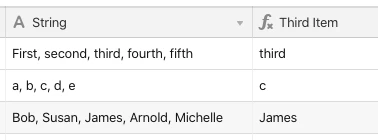
+4@Frank_Reagan If it’s a literal array, you’ll first need to convert it to a string. Array indexing isn’t currently possible using formulas. The easiest way to convert an array to a string is with the ARRAYJOIN() function:
ARRAYJOIN(array, ",")
Assuming you’ve got a string, there are at least three items in that string, and there are commas separating each item (as in your example), then this would work:
IF(String, REGEX_EXTRACT(String, "(?:[^,]*, *){2}([^,]*)(?:.*)"))
Your sample also has a space after each comma; this formula will also take that into account in case your data may include that.
This is incredibly helpful, Justin!
Can you explain this aspect of the formula?
"(?:[^,]*, *){2}([^,]*)(?:.*)"
I’d like to understand this more so that I can adapt it to find additional item numbers in a string list, not just the 3rd position. Would I get the fourth item with this modification:
"(?:[^,]*, *){3}([^,]*)(?:.*)"
For your entertainment, I have a working solution to find up to the 10th position within a string list (using multiple fields in order to increment and iterate through the list), but it is overly complex and requires too many helper fields in order to achieve:
• {Items_count} = count field of {Linked_records} field
• {Original_string} = convert {Linked_records} field into csv string
• {First_item} = LEFT({Original_string},FIND(", “,{Original_string})-1);
• {Remaining_items_1} = IF({Items_count}>1,MID({Original_string},LEN(LEFT({Original_string},FIND(”, “,{Original_string})+2)),LEN({Original_string})),”");
• {Second_item} = IF({Items_count}=2,{Remaining_items_1},LEFT({Remaining_items_1},FIND(", “,{Remaining_items_1})-1));
• {Remaining_items_2} = IF({Items_count}>2,MID({Remaining_items_1},LEN(LEFT({{Remaining_items_1},FIND(”, “,{Remaining_items_1})+2)),LEN({{Remaining_items_1})),”");
• {Third_item} = IF({Items_count}=3,{Remaining_items_2},LEFT({Remaining_items_2},FIND(", ",{Remaining_items_2})-1));
• Etc…
:grinning_face_with_sweat:
+21This is incredibly helpful, Justin!
Can you explain this aspect of the formula?
"(?:[^,]*, *){2}([^,]*)(?:.*)"
I’d like to understand this more so that I can adapt it to find additional item numbers in a string list, not just the 3rd position. Would I get the fourth item with this modification:
"(?:[^,]*, *){3}([^,]*)(?:.*)"
For your entertainment, I have a working solution to find up to the 10th position within a string list (using multiple fields in order to increment and iterate through the list), but it is overly complex and requires too many helper fields in order to achieve:
• {Items_count} = count field of {Linked_records} field
• {Original_string} = convert {Linked_records} field into csv string
• {First_item} = LEFT({Original_string},FIND(", “,{Original_string})-1);
• {Remaining_items_1} = IF({Items_count}>1,MID({Original_string},LEN(LEFT({Original_string},FIND(”, “,{Original_string})+2)),LEN({Original_string})),”");
• {Second_item} = IF({Items_count}=2,{Remaining_items_1},LEFT({Remaining_items_1},FIND(", “,{Remaining_items_1})-1));
• {Remaining_items_2} = IF({Items_count}>2,MID({Remaining_items_1},LEN(LEFT({{Remaining_items_1},FIND(”, “,{Remaining_items_1})+2)),LEN({{Remaining_items_1})),”");
• {Third_item} = IF({Items_count}=3,{Remaining_items_2},LEFT({Remaining_items_2},FIND(", ",{Remaining_items_2})-1));
• Etc…
:grinning_face_with_sweat:
Correct! :partying_face:
That is a regular expression. Regular expressions are wonderful for working on strings based on patterns. It can take some time to understand, which is why I recommend using a site like regex101.com to test regular expressions before using them in Airtable (be sure to pick the “Golang” option on the left if you use that site; that’s the flavor closest to what Airtable’s regex interpreter uses).
Let’s break it down into a few basic concepts first…
Parentheses are used to define groups. In that expression above, there are three defined groups. Sometimes you can locate things without grouping them first, but in this situation, using groups makes isolating specific things a lot easier.
Whenever a group begins with ?:, that means that everything else in the group should be located, but not returned. In other words, that group is just there as a reference to help find other items.
When you see a number in curly braces—e.g. {2}—that means to match the preceding item (or group, as in this case) that many times. You can also use multiple numbers to make the same match a range of times. For example, {2,5} indicates to match the preceding item at least 2 times, but not more than 5.
Now let’s dive into the first group. Temporarily stripping away the parentheses and the “ignore me” prefix, we have this:
[^,]*, *
Square braces indicate that any of the contained characters should be matched. However, this character collection begins with a caret ^ symbol, meaning that any characters except those that follow the caret should be matched. In short, match any character that’s not a comma.
The asterisk * says to match the preceding item zero or more times. When combined with the square brace collection, this says to look for zero or more characters that are not commas.
Then there’s a literal comma, which matches that single character. That’s followed by a space and another asterisk, meaning to match a space zero or more times.
The whole first group then translates into this: match—but don’t collect—any quantity of non-comma characters that are followed by a literal comma and zero or more spaces. When combined with the number in curly braces after it, it says to find that grouping exactly two times.
The next group— ([^,]*) — should be easier to understand now: match any quantity of non-comma characters. Because this group doesn’t have the ?: prefix, its contents will be captured (i.e. extracted).
The final group is similar to the first. It’s a non-capturing group that matches zero or more of any character (the period represents any single character)
To sum it up, that expression finds—but doesn’t capture—the first two stretches of text ending in commas (and, optionally, spaces), collects the third item up to—but not including—the comma after it, and then ignores everything else.
As you’ve correctly guessed, modifying it to capture any Nth item is just a matter of changing the number in the curly braces to N - 1.
+4Correct! :partying_face:
That is a regular expression. Regular expressions are wonderful for working on strings based on patterns. It can take some time to understand, which is why I recommend using a site like regex101.com to test regular expressions before using them in Airtable (be sure to pick the “Golang” option on the left if you use that site; that’s the flavor closest to what Airtable’s regex interpreter uses).
Let’s break it down into a few basic concepts first…
Parentheses are used to define groups. In that expression above, there are three defined groups. Sometimes you can locate things without grouping them first, but in this situation, using groups makes isolating specific things a lot easier.
Whenever a group begins with ?:, that means that everything else in the group should be located, but not returned. In other words, that group is just there as a reference to help find other items.
When you see a number in curly braces—e.g. {2}—that means to match the preceding item (or group, as in this case) that many times. You can also use multiple numbers to make the same match a range of times. For example, {2,5} indicates to match the preceding item at least 2 times, but not more than 5.
Now let’s dive into the first group. Temporarily stripping away the parentheses and the “ignore me” prefix, we have this:
[^,]*, *
Square braces indicate that any of the contained characters should be matched. However, this character collection begins with a caret ^ symbol, meaning that any characters except those that follow the caret should be matched. In short, match any character that’s not a comma.
The asterisk * says to match the preceding item zero or more times. When combined with the square brace collection, this says to look for zero or more characters that are not commas.
Then there’s a literal comma, which matches that single character. That’s followed by a space and another asterisk, meaning to match a space zero or more times.
The whole first group then translates into this: match—but don’t collect—any quantity of non-comma characters that are followed by a literal comma and zero or more spaces. When combined with the number in curly braces after it, it says to find that grouping exactly two times.
The next group— ([^,]*) — should be easier to understand now: match any quantity of non-comma characters. Because this group doesn’t have the ?: prefix, its contents will be captured (i.e. extracted).
The final group is similar to the first. It’s a non-capturing group that matches zero or more of any character (the period represents any single character)
To sum it up, that expression finds—but doesn’t capture—the first two stretches of text ending in commas (and, optionally, spaces), collects the third item up to—but not including—the comma after it, and then ignores everything else.
As you’ve correctly guessed, modifying it to capture any Nth item is just a matter of changing the number in the curly braces to N - 1.
Thank you so much @Justin_Barrett! This worked and is SO much easier and efficient than my workaround :grinning_face_with_big_eyes: I appreciate your explanation and resources for REGEX and I am looking forward to learning & practicing it more!
 +25
+25Correct! :partying_face:
That is a regular expression. Regular expressions are wonderful for working on strings based on patterns. It can take some time to understand, which is why I recommend using a site like regex101.com to test regular expressions before using them in Airtable (be sure to pick the “Golang” option on the left if you use that site; that’s the flavor closest to what Airtable’s regex interpreter uses).
Let’s break it down into a few basic concepts first…
Parentheses are used to define groups. In that expression above, there are three defined groups. Sometimes you can locate things without grouping them first, but in this situation, using groups makes isolating specific things a lot easier.
Whenever a group begins with ?:, that means that everything else in the group should be located, but not returned. In other words, that group is just there as a reference to help find other items.
When you see a number in curly braces—e.g. {2}—that means to match the preceding item (or group, as in this case) that many times. You can also use multiple numbers to make the same match a range of times. For example, {2,5} indicates to match the preceding item at least 2 times, but not more than 5.
Now let’s dive into the first group. Temporarily stripping away the parentheses and the “ignore me” prefix, we have this:
[^,]*, *
Square braces indicate that any of the contained characters should be matched. However, this character collection begins with a caret ^ symbol, meaning that any characters except those that follow the caret should be matched. In short, match any character that’s not a comma.
The asterisk * says to match the preceding item zero or more times. When combined with the square brace collection, this says to look for zero or more characters that are not commas.
Then there’s a literal comma, which matches that single character. That’s followed by a space and another asterisk, meaning to match a space zero or more times.
The whole first group then translates into this: match—but don’t collect—any quantity of non-comma characters that are followed by a literal comma and zero or more spaces. When combined with the number in curly braces after it, it says to find that grouping exactly two times.
The next group— ([^,]*) — should be easier to understand now: match any quantity of non-comma characters. Because this group doesn’t have the ?: prefix, its contents will be captured (i.e. extracted).
The final group is similar to the first. It’s a non-capturing group that matches zero or more of any character (the period represents any single character)
To sum it up, that expression finds—but doesn’t capture—the first two stretches of text ending in commas (and, optionally, spaces), collects the third item up to—but not including—the comma after it, and then ignores everything else.
As you’ve correctly guessed, modifying it to capture any Nth item is just a matter of changing the number in the curly braces to N - 1.
additional thanks for that info. regular expressions is something new for me, and when I tried to write my own, it passed test, but refused to work here. when i tried to change random options, i never expected it should be Golang.
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.
Sorry, we're still checking this file's contents to make sure it's safe to download. Please try again in a few minutes.
OKSorry, our virus scanner detected that this file isn't safe to download.
OK