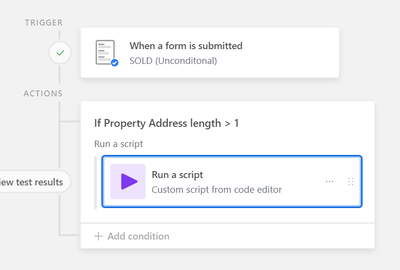
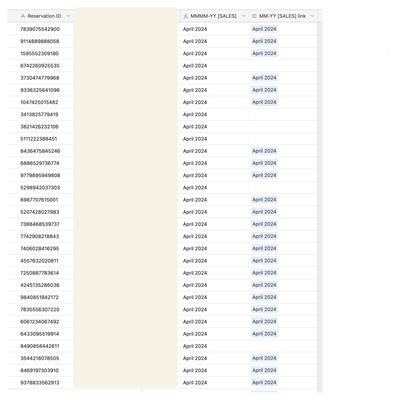
Formula If and dateadd
Hello airtable community, I have this following formula but dateadd does not display the operation in the result thank you for your feedbackFranck IF({Date début package} != '', {Date début package},IF({Date début expl 23} != '', {Date début expl 23...
- 19 Views
- 0 replies
- 0 kudos