

I wanted to share with the community a practice that we are doing as we start our AI journey for Airtable. It took a bit time to get through our security review but got the green light and we’re off!!
Airtable provides a nice selection of models between ChatGPT and Claude. Reading the options some are noted to be “Low Cost”. So we had a few key questions that needed to be answered:
- Which model performs the best for our use case?
- How many credits does each model use?
Our goal - pick the model(s) that ultimately produces the best results while keeping cost the lowest
We setup a simple Design of Experiment (DOE) once we completed our build and had done some thorough prompt engineering. For our specific use case, our build was to ingest applications that needed to be scored against a set criteria.
Build Setup for using AI: 3 fields
- Field 1 - Score the application and produce a numeric whole value (e.g. 5)
- Field 2 - Score the application and produce a numeric value with justification for the score
- Field 3 - Analyze the application and determine what percentage of it was AI generated vs human created (emulate something close to what GPTZero does)
Baseline:
- We created very specific applications that had clear baseline results
- One we completely created from AI
- One we did not use any AI
- One with terrible answers to generate a low score on purpose
- One with incredible answers to generate the best score possible
Based on this, the image below shows our results:
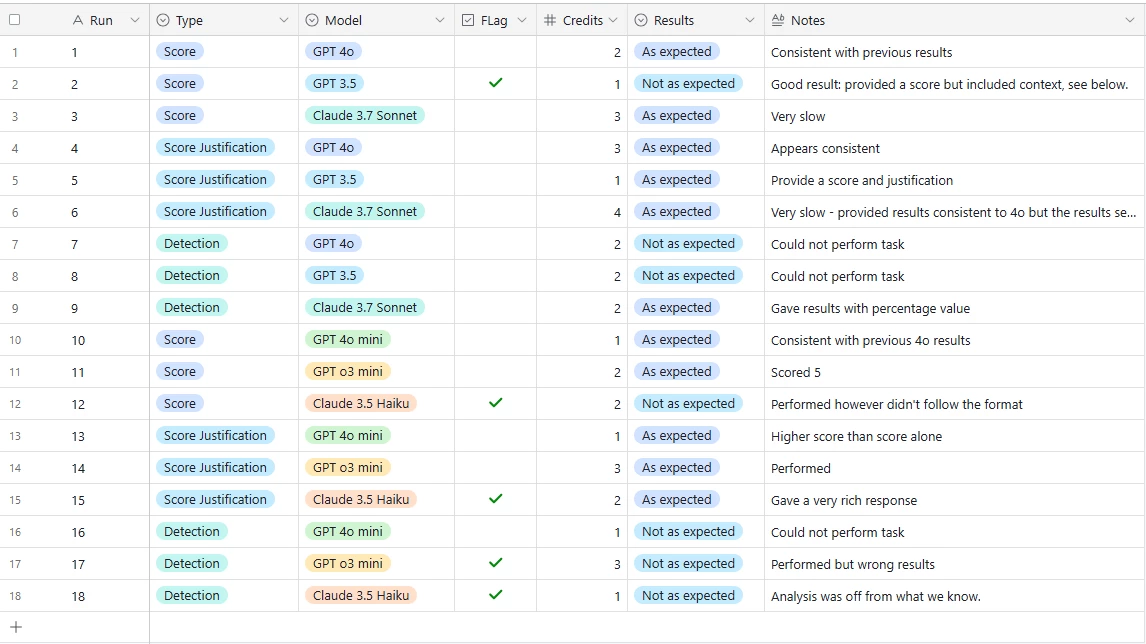
For our use case, we determined GPT 4omini gave just as good results for the lowest price in Scoring and providing justification. However for detection, GPT was not good vs Claude 3.7 Sonnet (only). In the end we scrapped doing the AI detection piece as it was not entirely reliable. This study did highlight many great things for us. It was fast and easy to setup and test.
This is now our standard practice going forward for our quality control process in AI builds.