

Hi everyone, Kenzo here from the Airtable Product team.
Today we’re rolling out Web Tables in Omni (AI Labs) — a new way to research people and companies, and to power workflows such as sales prospecting, company research trackers, and recruiting outreach.
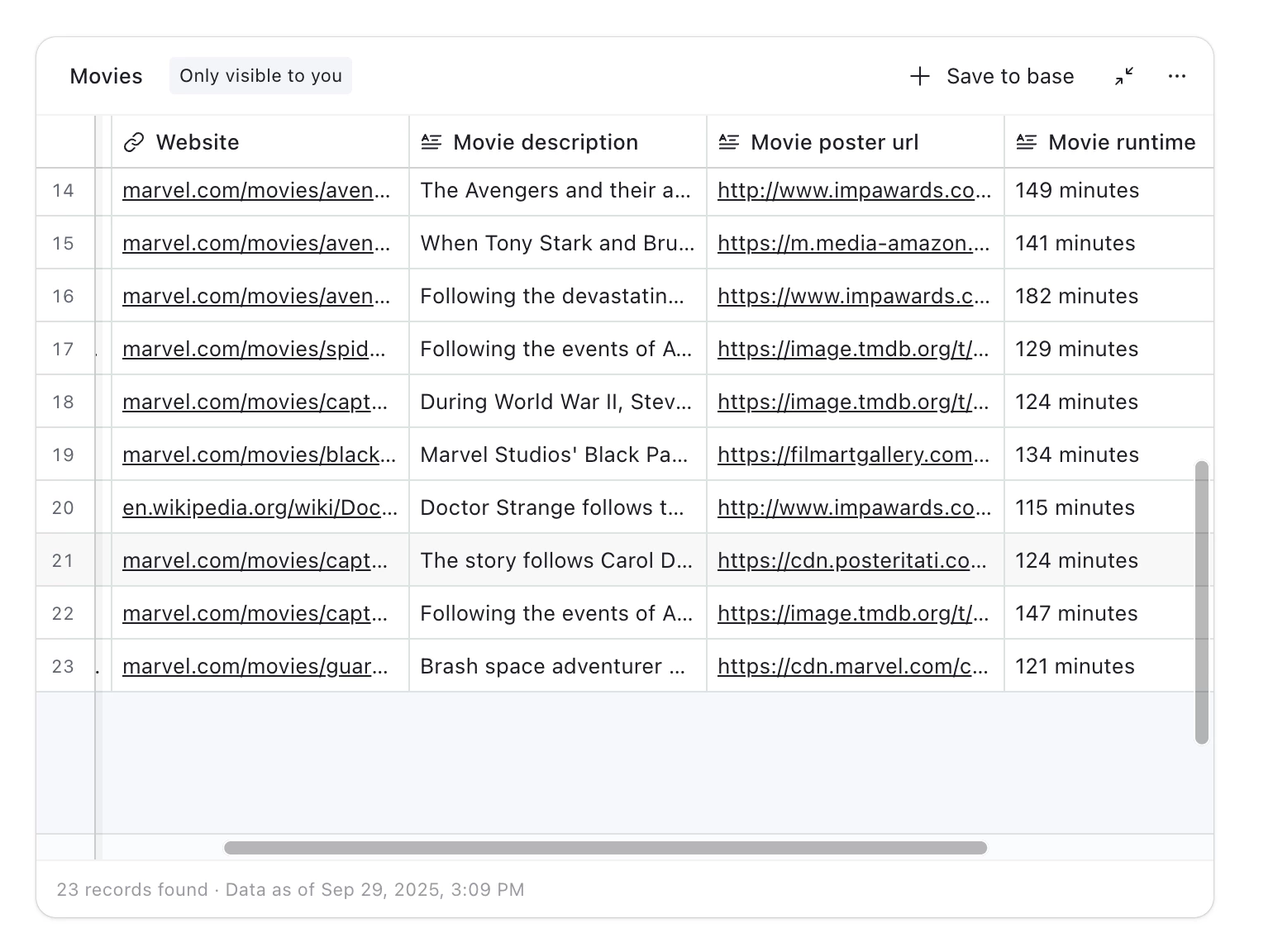
Web Tables let you create structured datasets of people and companies from the web, directly in Airtable.
This unlocks new kinds of apps you can build without manual data collection or cleanup, such as:
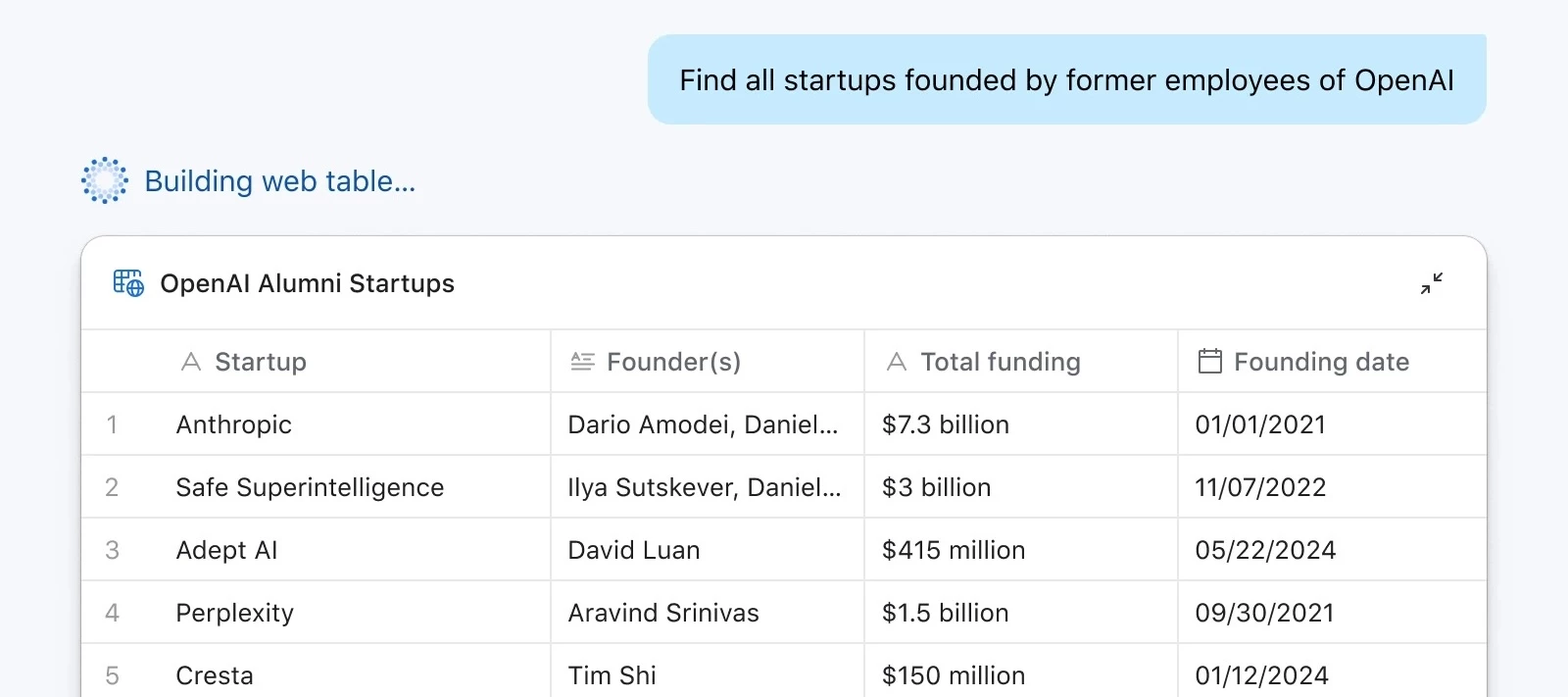
- Company Research Tracker – monitor startups, competitors, or YC companies with founder and funding details, then track them in your company tracker app. Example prompt: Find all Y Combinator companies founded since 2022 that are in the fintech or AI sectors.
- Recruiting Pipeline – find candidates, their roles, and recent job changes, then add them to your Recruiting base and link them to open roles. Example prompt: Find all software engineers in San Francisco who have recently left Stripe or Coinbase.
- Sales CRM – build prospect lists with company size, funding stage, and key contacts, then assign records to sales reps and track deal progress in your CRM base. Example prompt: Find all Series A SaaS companies in North America with over 50 employees and a VP of Sales hired in the last 6 months.
- Event Venue Database – manage event spaces with capacity, location, and then link venues to upcoming events in your Marketing Events base. Example prompt: Find all conference centers in New York City with seating for over 500 people and recent corporate event bookings.
Omni crawls and enriches web data into a clean table you can explore, filter, and connect to your Airtable workflows.
How to try it today
Workspace admins can enable AI Labs from Account > Workspace Settings. Once enabled, select Web Tables in Omni and describe the dataset you want to build.
Important details:
- While Web Tables is in AI Labs, credits will not be charged.
- Web Table queries involve deeper crawling and sourcing, so they may take several minutes and use more credits than a normal search.
- The feature is under active development—your feedback will directly shape improvements.