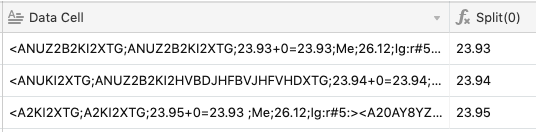
This is the data in my cell
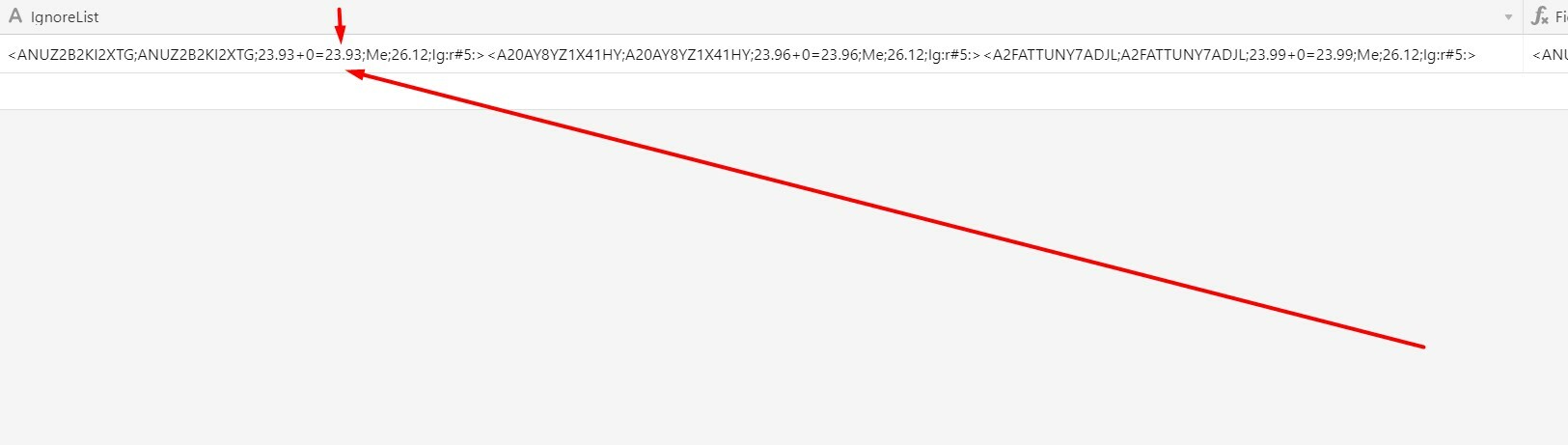
<ANUZ2B2KI2XTG;ANUZ2B2KI2XTG;23.93+0=23.93;Me;26.12;Ig:r#5:><A20AY8YZ1X41HY;A20AY8YZ1X41HY;23.96+0=23.96;Me;26.12;Ig:r#5:><A2FATTUNY7ADJL;A2FATTUNY7ADJL;23.99+0=23.99;Me;26.12;Ig:r#5:>
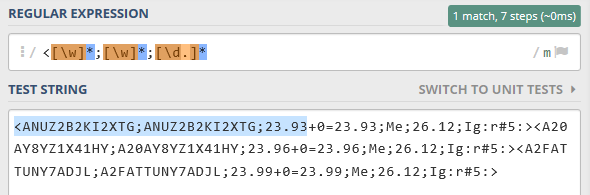
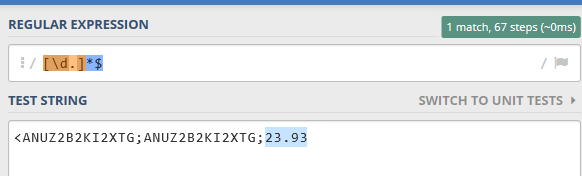
I am trying to extract the first number which is “23.93” from the cell