Hi!
This one seems quite easy, but having a tough time to loop LEFT and RIGHT to make it work …
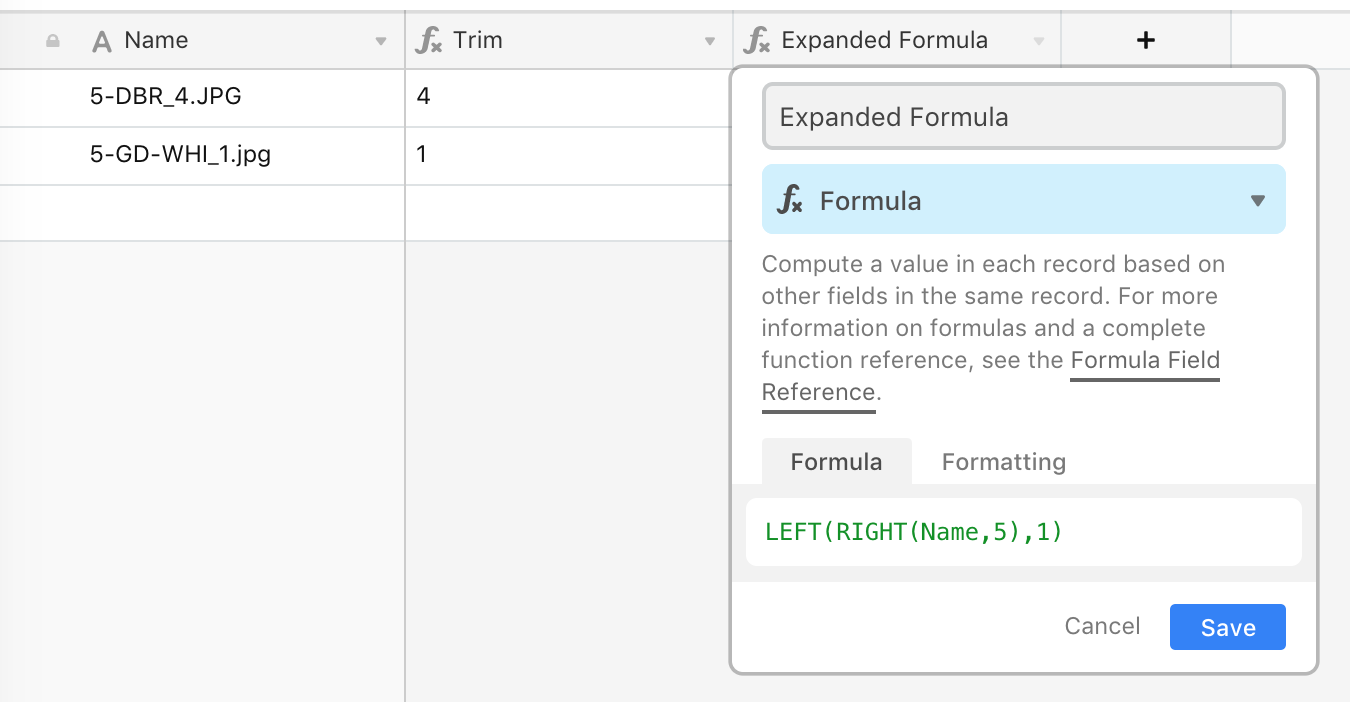
I have the following examples
5-DBR_4.JPG
5-GD-WHI_1.jpg
In both instances, I want to extract the text between the “_” and the “.JPG”, so “4” and “1” respectively.
This is to populate an {Position} field.
What is the right formula to use for this?