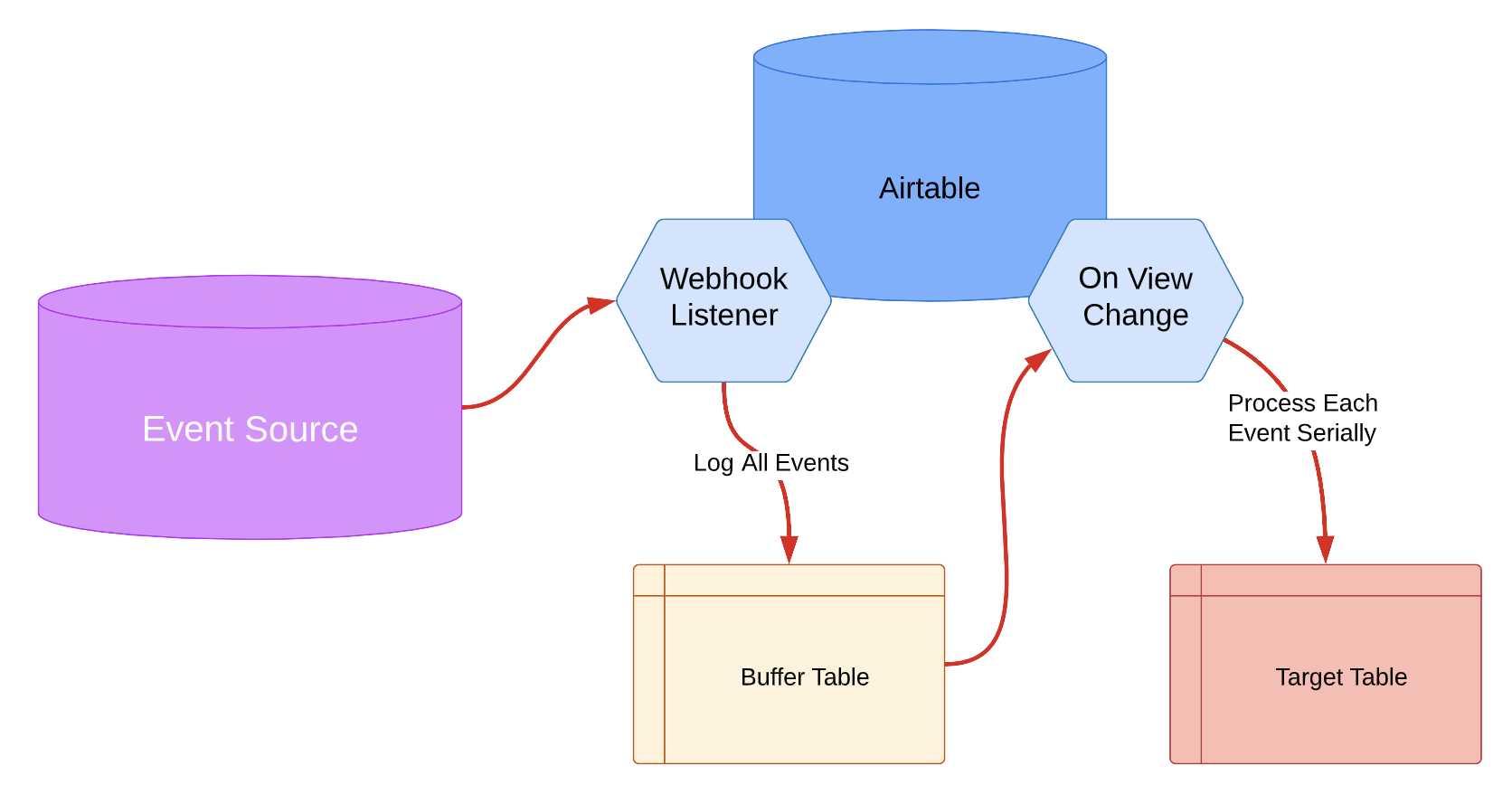
Hi Airtable Community,
I have a base that receives and manipulates data coming in using a webhook. Data comes in as a single record (so each webhook brings in a single record of data) and that single record needs to be processed completely before the next record can be considered. In other words, the automation needs to run to completion on one record before the automation starts again for the next record.
The automation consists of 1 create record action followed by 5 script actions, and is initiated by the receival of a webhook. The automation runs as expected when tested, however I have started to notice missing data assignments that should have been completed by one or two of the script actions. I suspect this may be because a number of webhooks are received within quick succession, which leads to automations kicking off before the previous one has been completed?
Does this sounds plausible? And if so, are there any suggestions on how to resolve this issue?
Cheers,
Ryan.