I am sure this has been asked before, I have searched high and low, and have found no solution to do the following, even with Zapier.
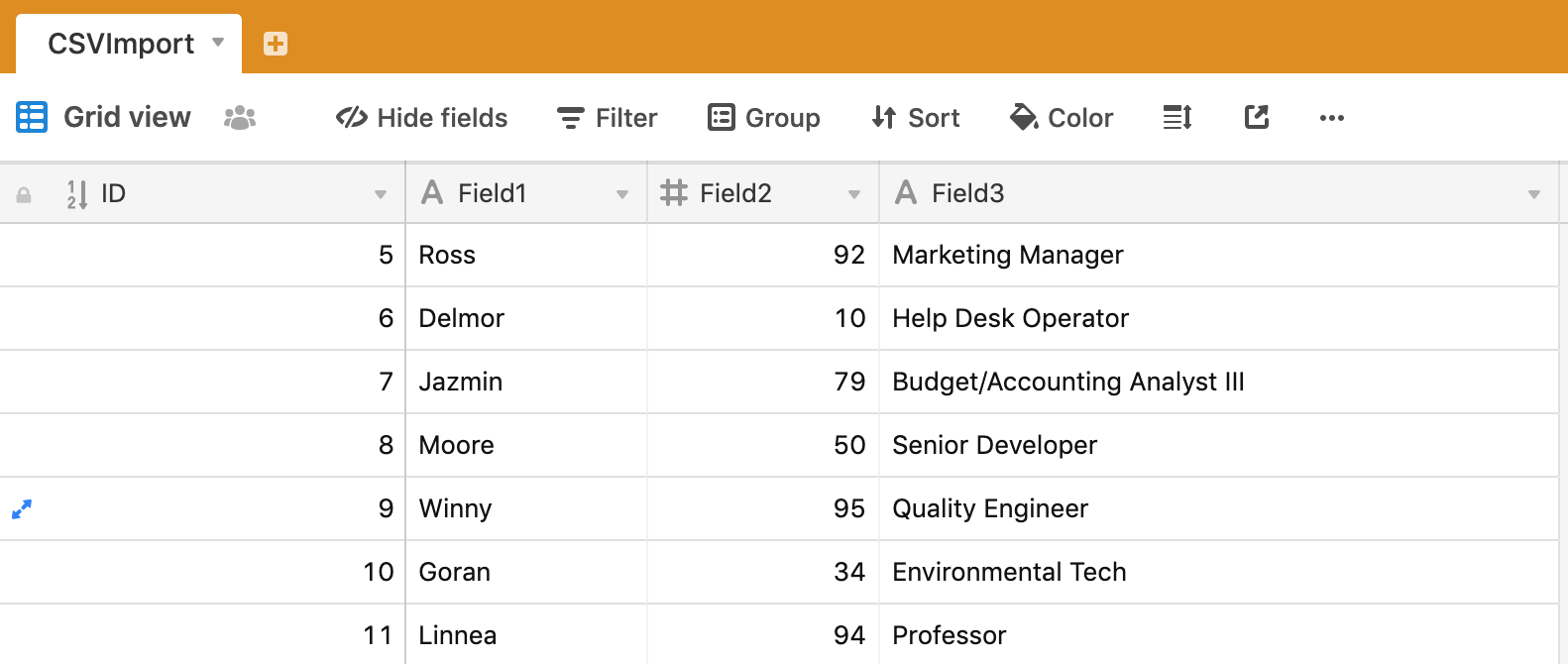
I have a .csv file that I want to import direct to Airtable.
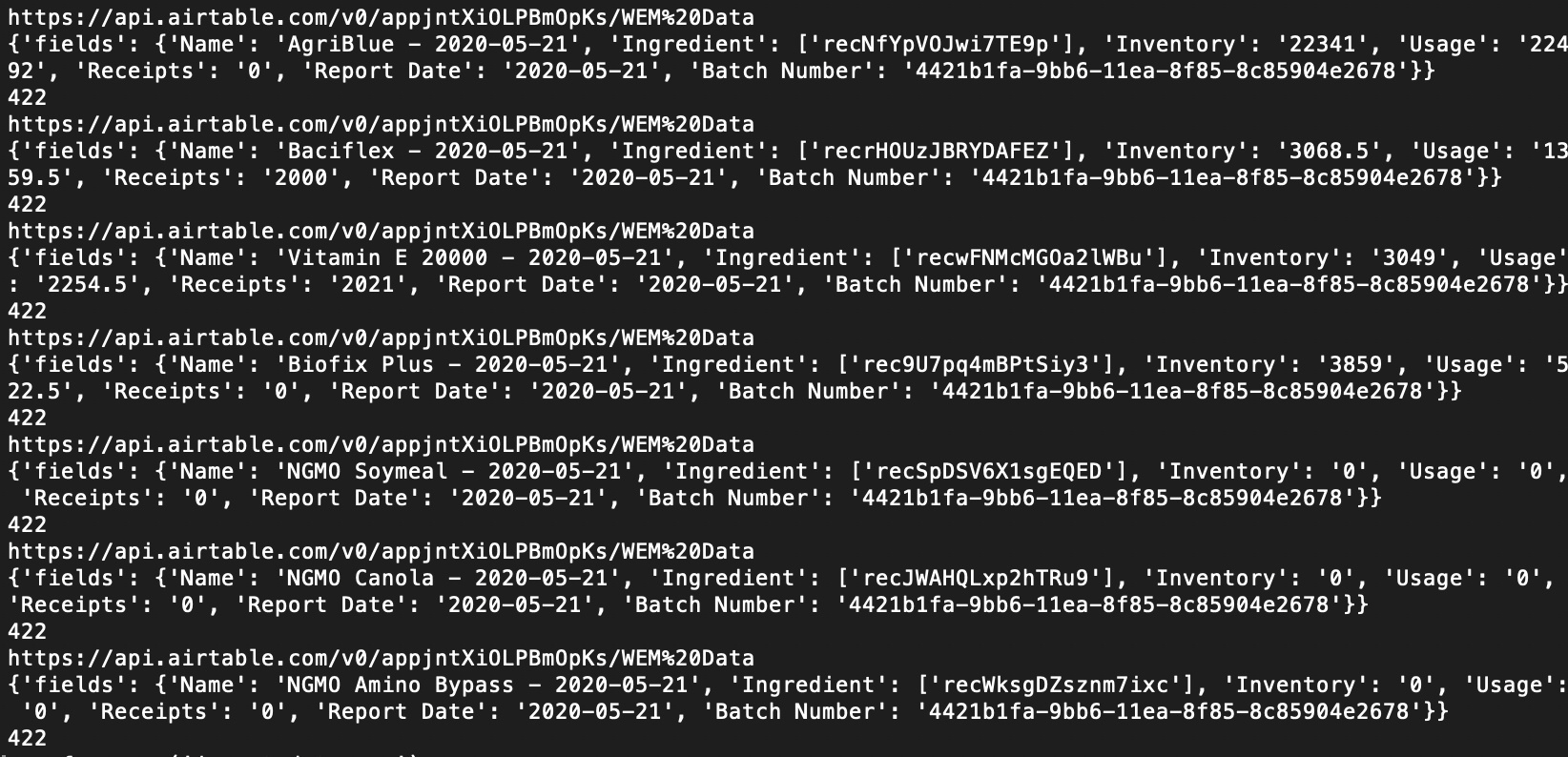
The .csv was created programatically (in Node.js), and exists on a Google Cloud VM (Red Hat Linux).
There is nothing in the AirTable API that allows for direct insertion of a full CSV as a new tab in an existing base.
I want to name the tab in the existing base the same name as the CSV file, without the .csv extension.
If anyone has actually done this successfully, and smoothly, please respond. The only articles I can find on how to import a CSV to AirTable involve a human being and clicking in the browser.