

An Airtable user tagged me with a question offline today. It caught my attention.
… has Airtable (or have you) made any progress in using Vega Lite for non-table-based data?
I believe he's referring to the ability to blend Airtable data with external data to product visualizations. This is a data-sciency thing that touches on aggregations.
Allow me to reframe the narrative.
- Analytics designed to expose findings about data sets is typically based on aggregations. I often refer to these as viz-ready data.
- Aggregations are post-processes that are typically applied over collections of transactions or observations that are detailed. It's the data no one wants to look at except for perhaps auditors or data scientists designing aggregations.
- Airtable has rollups and other mechanisms to create aggregations. They're weak, poorly implemented, require new fields and keys, and almost always slow.
- Dynamic aggregations in a late-binding process (at viz-time) are needed because data changes frequently, and many systems require near-real-time interpretation. This is especially true in transportation, logistics, war fighting, and medicine.
- Often, aggregations require a blend of external data with internal data. This adds a level of complexity to reporting and data visualization requirements.
I recently wrote about dynamic aggregations from Airtable data here. The article discusses using Airtable data for natural language queries that also respond in written narratives like ChatGPT. For example… with customer survey data, a query like this might be on a marketing executive's mind.
What are the top three preferences our customers have for maintenance?
The answer might look like this. Note - this is an actual Airtable script that did this across 10,000 surveys in about 2 seconds.
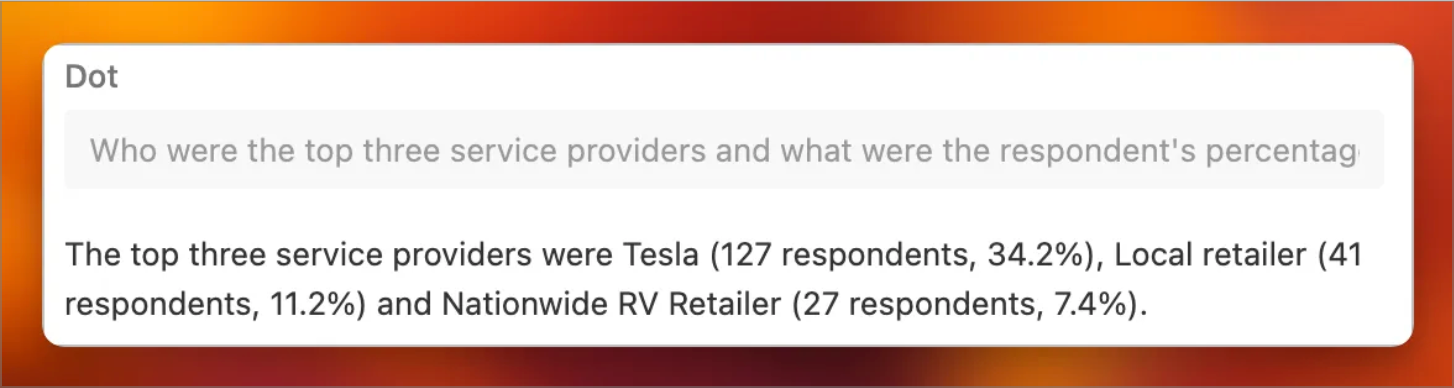
But in that post, two items may be particularly relevant to this question:
- Aggregations must be dynamic. They should seamlessly happen regardless of the shape of the data or the number of fields.
- Prompts engineered to use aggregations must intelligently scale. Artificial intelligence should be used to build the prompt where the variety of classes and/or the number of fields is high.
Number one suggests that the aggregation should continue functioning without code changes as the data schema changes. Number two implies that as the width of the schema grows, AI inferencing performance should remain relatively constant.
None of this AI banter matters unless there's a relevant connection between this question and data visualizations. I call your attention to this tweet and this one.
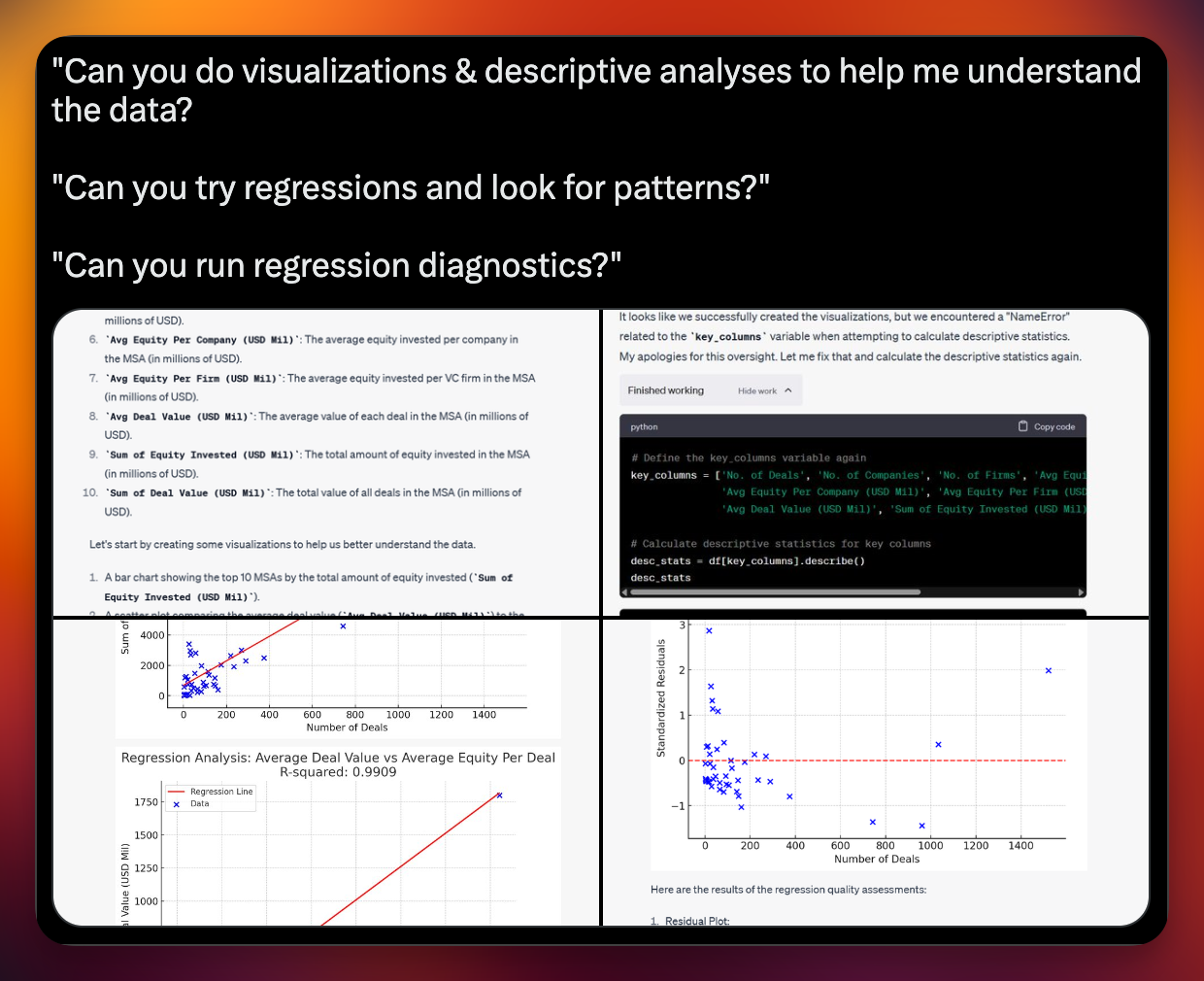
I have a hunch that the future of data science and visuals has already changed forever. While Vega-Lite or the many charting extensions that Airtable supports may still matter, it may not be in the way you may think it does.
On the very near horizon, while we continue to build scripts, it won't be to generate data visuals. Instead, our low code development efforts will be used to build data aggregations that are used in AI learner prompts that, in turn, will generate data visuals.
The future of #low-code may need to do less to do more. Its purpose may eventually vanish, at least as it pertains to data sciency things. This realization dovetails with another recent understanding - AI is not an app; it's a UI that transforms words into an API. Read more here.