@Jeff_Maynard, what you are looking for is the REGEX_EXTRACT() formula function. I can show you an example using the following sample text:
Here is a possible regular expression that you could use: ^(?:\w+\s){3}(\w+).
Explanation: The ^ marks the start of the string. A (?:...) marks a non-capturing group. Since we don’t want to capture the first three words, I wrap them in a non-capturing group and match for them. A \w matches any word character, the + says match as many as possible until you hit a non-word character (i.e. a space). The \s matches any white space character. This means the following section matches the first word and the space that follows it: (?:\w+\s). To match it three times, add {3}. Now that you have matched the first three words, all you need to do is extract the last one. A capturing group signifies what it is that you want to extract, represented as such: (...). To match a word, simply do the same as above but leave out the white space: \w+. Thus, the final expression is ^(?:\w+\s){3}(\w+).
Here is a screenshot of what it could possibly look like once inputted (formula used: REGEX_EXTRACT({Sample Text}, "^(?:\\w+\\s){3}(\\w+)")):
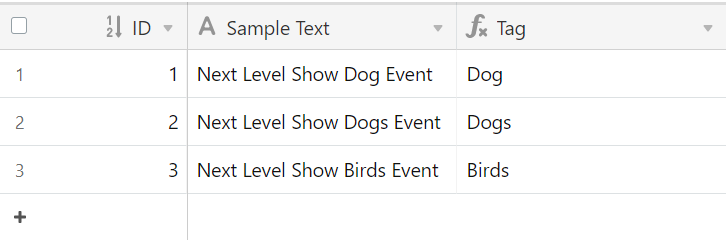
This should hopefully solve your problem!
@Jeff_Maynard, what you are looking for is the REGEX_EXTRACT() formula function. I can show you an example using the following sample text:
Here is a possible regular expression that you could use: ^(?:\w+\s){3}(\w+).
Explanation: The ^ marks the start of the string. A (?:...) marks a non-capturing group. Since we don’t want to capture the first three words, I wrap them in a non-capturing group and match for them. A \w matches any word character, the + says match as many as possible until you hit a non-word character (i.e. a space). The \s matches any white space character. This means the following section matches the first word and the space that follows it: (?:\w+\s). To match it three times, add {3}. Now that you have matched the first three words, all you need to do is extract the last one. A capturing group signifies what it is that you want to extract, represented as such: (...). To match a word, simply do the same as above but leave out the white space: \w+. Thus, the final expression is ^(?:\w+\s){3}(\w+).
Here is a screenshot of what it could possibly look like once inputted (formula used: REGEX_EXTRACT({Sample Text}, "^(?:\\w+\\s){3}(\\w+)")):
This should hopefully solve your problem!
This is brilliant, and possibly the best explanation of REGEX that I have ever seen in my life!
@Jeff_Maynard, what you are looking for is the REGEX_EXTRACT() formula function. I can show you an example using the following sample text:
Here is a possible regular expression that you could use: ^(?:\w+\s){3}(\w+).
Explanation: The ^ marks the start of the string. A (?:...) marks a non-capturing group. Since we don’t want to capture the first three words, I wrap them in a non-capturing group and match for them. A \w matches any word character, the + says match as many as possible until you hit a non-word character (i.e. a space). The \s matches any white space character. This means the following section matches the first word and the space that follows it: (?:\w+\s). To match it three times, add {3}. Now that you have matched the first three words, all you need to do is extract the last one. A capturing group signifies what it is that you want to extract, represented as such: (...). To match a word, simply do the same as above but leave out the white space: \w+. Thus, the final expression is ^(?:\w+\s){3}(\w+).
Here is a screenshot of what it could possibly look like once inputted (formula used: REGEX_EXTRACT({Sample Text}, "^(?:\\w+\\s){3}(\\w+)")):
This should hopefully solve your problem!
Thank you very much. I really appreciate your help. I will jump on this afternoon and it gives a try!
@Jeff_Maynard, what you are looking for is the REGEX_EXTRACT() formula function. I can show you an example using the following sample text:
Here is a possible regular expression that you could use: ^(?:\w+\s){3}(\w+).
Explanation: The ^ marks the start of the string. A (?:...) marks a non-capturing group. Since we don’t want to capture the first three words, I wrap them in a non-capturing group and match for them. A \w matches any word character, the + says match as many as possible until you hit a non-word character (i.e. a space). The \s matches any white space character. This means the following section matches the first word and the space that follows it: (?:\w+\s). To match it three times, add {3}. Now that you have matched the first three words, all you need to do is extract the last one. A capturing group signifies what it is that you want to extract, represented as such: (...). To match a word, simply do the same as above but leave out the white space: \w+. Thus, the final expression is ^(?:\w+\s){3}(\w+).
Here is a screenshot of what it could possibly look like once inputted (formula used: REGEX_EXTRACT({Sample Text}, "^(?:\\w+\\s){3}(\\w+)")):
This should hopefully solve your problem!
It worked! Can I buy you a coffee?
It worked! Can I buy you a coffee?
@Jeff_Maynard It’s enough for me to know that it worked! Thank you for the offer, though!
