I have addresses in multiple lines and am using REGEX EXTRACT in Airtable to separate the components (street address, suburb, state, post code) before sending them on for shipping labels.
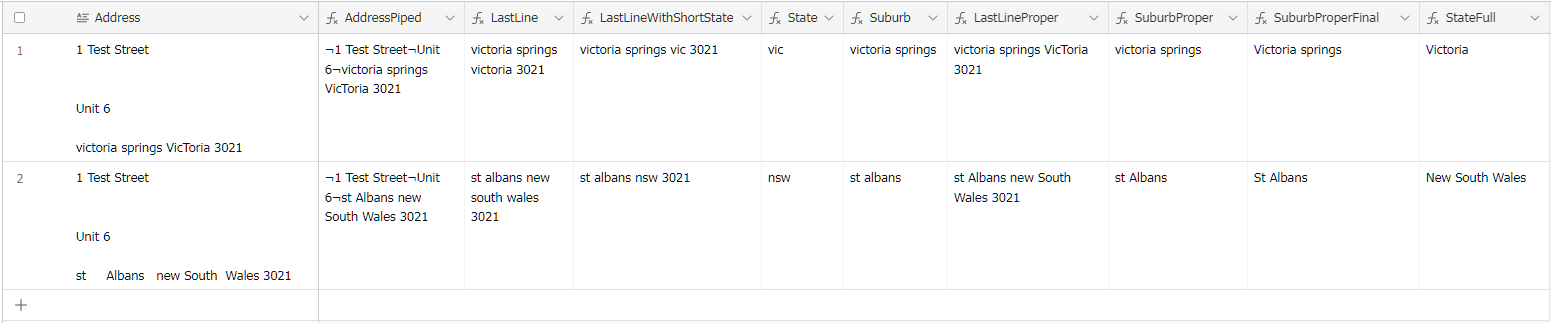
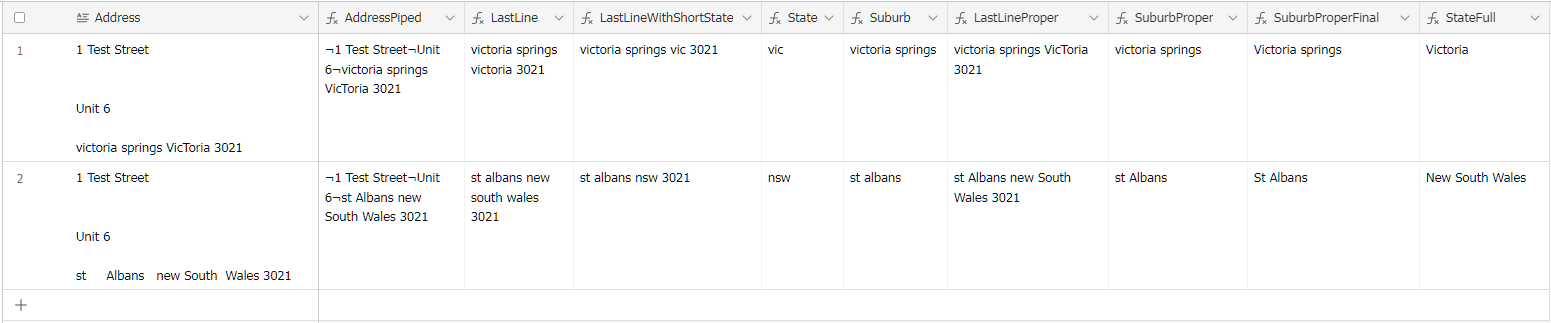
I've used REGEX_EXTRACT({text input}, "^(?:.*\n){1}") to extract the first line and this works in most cases except when the street address is over two lines (see example B).
Can someone please help me with a REGEX EXTRACT that extracts every line except the last line (whether the address is 2 or 3 lines)?
Or is there a simpler solution I'm not aware of?
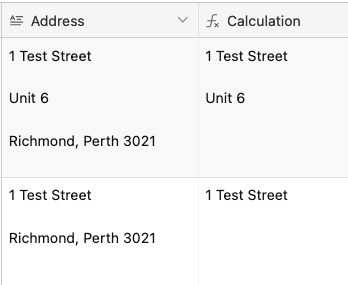
Example A
1 Test Street
Richmond, Perth 3021
Example B
1 Test Street
Unit 6
Richmond, Perth 3021
For reference on how I'm dealing with the rest of the components...
I've used REGEX_EXTRACT({text input}, "^.\r?\n(.)") to extract the last line (Subrub, State, Postcode) and then used REGEX_EXTRACT({text input}, ".*(\d{4})") to extract the post code.
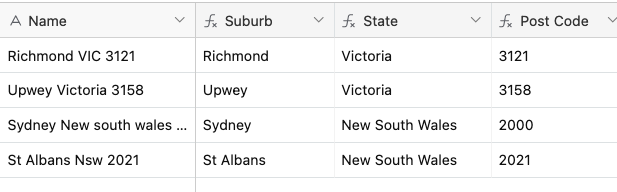
Once I have the post code I'm matching it against a database to find the Suburb and State. I did this because I believe it's too difficult to do a REGEX that will extract the Suburb, State and Postcode individually. I think it's too difficult because both the Suburb and State can be one, two or three words long. If you have a better solution I'm all ears!