If I’m understanding you correctly, this regex will do the job here:
REGEX_EXTRACT(URL,"https://") & "\n" & REGEX_EXTRACT(URL,"https://(.*)/") & "\n" & REGEX_EXTRACT(URL,"https.*\\.[com|net|org]{3,5}\\/(.*)")
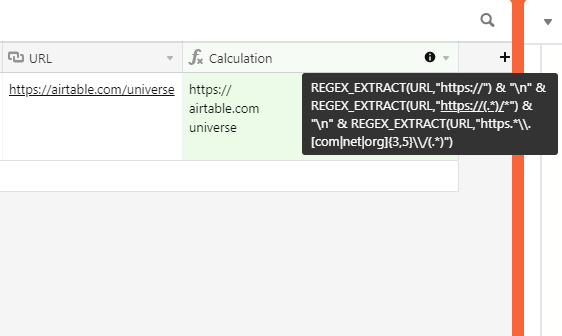
If you want to match the final slash in the address, just push the \/ construct into the parantheses-bound capture group at the end. The regex itself is a bit hacky but I’ll chalk that up as a plus in case you wanted to improve upon it and learn a few things yourself. :grinning_face_with_sweat:
this is very good stuff - thanks!
I managed the same result through a bunch of text function, this solution is way more sophisticated.
Any recommended resources to learn REGEX?


