TIA - this community is amazing and so helpful when I can't get my head around these more tricky ones. but I am learning more and more!
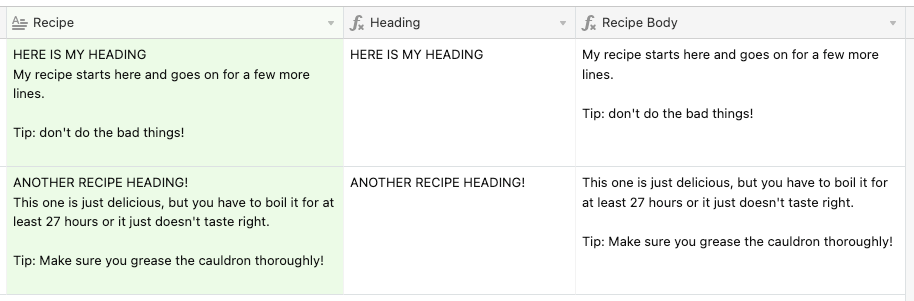
I have a bunch of method steps for our recipes:
COOK THE SALMON
Pat dry salmon with paper towel, remove the skin and cut into bite size pieces, discarding the skin. Add salmon, olives and courgette to the pot. Simmer, gently stirring occasionally, for 5-6mins, or until the salmon is cooked through and all the veggies are tender. Remove from heat. Check seasoning. "
MAKE THE AVOCADO DIP
Cut lemon into wedges.
Halve avocado, remove the stone and scoop out flesh with a spoon. Place avocado into a third medium bowl and mash with fork until smooth. Mix in aioli and (1/2 tbsp/1 tbsp) lemon juice. Season with salt, pepper and more lemon juice to taste. Set aside.
TIP: If you prefer, add avocado to the salad in STEP 5 and serve aioli on the side. "
MAKE THE HERBY VINAIGRETTE
Finely chop (half/whole) pack coriander, including the stalks. Add to small bowl with (1 tsp/2 tsp) honey, (2 tbsp/4 tbsp) olive oil and (1 tbsp/2 tbsp) white wine vinegar. Stir together until combined. Season to taste with salt and pepper. Set aside.
TIP: You may use your preferred sweetener instead of honey."
You can see they are all different.
I want to have one column for the heading (in caps) and another column for the method directions.
Do you think I'll have any joy with this one?
thanks!