The SimpleScraper (go to simplescraper dot io) Chrome extension looks super powerful and useful for sucking up data into Airtable!

Page 1 / 2
Indeed it is. However, there are many issues with scraping data on the web and one is the possibility that the domain doing the scraping will be blacklisted from the content being scraped. As such, don’t look for Airtable to implement this functionality on airtable.com anytime soon.
Another issue is the ToS of any given content site. If you violate it, your account may be suspended. Airtable should fear getting in between its users and their non-Airtable data.
Lastly, security context. Scraping data from secure sites is really risky and wrought with a variety of security issues that Airtable would need to divert resources to. Are you sure you want to distract these folks from the core functionality of their solution?
Indeed it is. However, there are many issues with scraping data on the web and one is the possibility that the domain doing the scraping will be blacklisted from the content being scraped. As such, don’t look for Airtable to implement this functionality on airtable.com anytime soon.
Another issue is the ToS of any given content site. If you violate it, your account may be suspended. Airtable should fear getting in between its users and their non-Airtable data.
Lastly, security context. Scraping data from secure sites is really risky and wrought with a variety of security issues that Airtable would need to divert resources to. Are you sure you want to distract these folks from the core functionality of their solution?
Thanks for your perspective.
I don’t think that the issues you raised apply here, given that the extension is running in the user’s browser context, where it can access all the information I can access. Therefore, Airtable’s domain is unlikely to be blacklisted because the extension is accessing the web resource from the user’s IP address.
I’m unclear what TOS I might be violating if I copy content from a webpage, even if it’s restricted access. I can always save a webpage to my harddrive, or copy the text manually and put it into an Airtable base myself… what difference does it make if I use a tool for that purpose? The law has already made it clear that websites can’t deny web scrapers… (see arstechnica dot com/tech-policy/2019/09/web-scraping-doesnt-violate-anti-hacking-law-appeals-court-rules/).
The Airtable extension is simply automating me having to copy and paste content that I can already see, so I don’t see how there’s any additional security concerns here. The data is going to get into my base one way or another; of course it would be best if the scraper ran locally and then uploaded the data directly to Airtable, and so presuming that, I’m not immediately seeing how your concerns apply.
Perhaps to clarify my point: the SimpleScraper functionality should run on the client side without requiring any requests from Airtable to the page being scraped.
Thanks for your perspective.
I don’t think that the issues you raised apply here, given that the extension is running in the user’s browser context, where it can access all the information I can access. Therefore, Airtable’s domain is unlikely to be blacklisted because the extension is accessing the web resource from the user’s IP address.
I’m unclear what TOS I might be violating if I copy content from a webpage, even if it’s restricted access. I can always save a webpage to my harddrive, or copy the text manually and put it into an Airtable base myself… what difference does it make if I use a tool for that purpose? The law has already made it clear that websites can’t deny web scrapers… (see arstechnica dot com/tech-policy/2019/09/web-scraping-doesnt-violate-anti-hacking-law-appeals-court-rules/).
The Airtable extension is simply automating me having to copy and paste content that I can already see, so I don’t see how there’s any additional security concerns here. The data is going to get into my base one way or another; of course it would be best if the scraper ran locally and then uploaded the data directly to Airtable, and so presuming that, I’m not immediately seeing how your concerns apply.
Perhaps to clarify my point: the SimpleScraper functionality should run on the client side without requiring any requests from Airtable to the page being scraped.
This may indeed be the case today. You certainly know more about it than I do. However, are you certain that there would be no advantage to running some aspect of this technology on servers if in your hypothetical recommendation that SimpleScraper were acquired by Airtable? What would be the point of buying a scraper technology of you didn’t intend to integrate it in some way that creates competitive advantage.
But even so, how can you be so certain that the chrome extension you are using doesn’t interact with a server that performs scraping activity on your behalf?

To me, what “scrape in the cloud” means is far different from “scraping the cloud”. It suggests that there are process activities that may indeed be configured and managed in your browser, but which are actually performed by proxy services elsewhere.
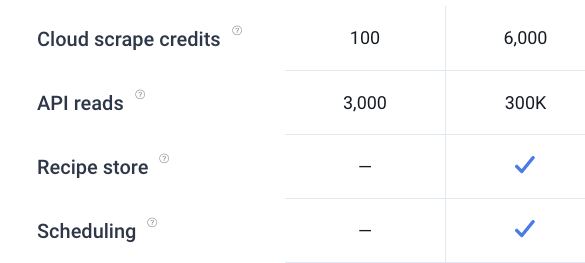
If you can schedule a scrape and close your browser, how do you think that works? Surely, it cannot run usolely] in your browser.
I’ve worked for a few companies that provide a variety of data harvesting technologies (import.io) and every one of them utilized servers to do the heavy lifting because browsers are (a) inefficient, (b) unable to pace themselves, (c ) unable to spread requests across multiple IPs, multiple user-agents and domains, and (d) are miserable tools where same-origin security policies come into play.
I think scraping is a fine activity and it’s wonderful to utilize these tools to acquire data. My comment was simply to point out that …
- Airtable is not likely to get into the data scraping business;
- There are lots of potential issues with scraping (technical and otherwise);
- Airtable has some pretty big competitive gaps in their solution; scraping is not going to help to close those gaps.
This may indeed be the case today. You certainly know more about it than I do. However, are you certain that there would be no advantage to running some aspect of this technology on servers if in your hypothetical recommendation that SimpleScraper were acquired by Airtable? What would be the point of buying a scraper technology of you didn’t intend to integrate it in some way that creates competitive advantage.
But even so, how can you be so certain that the chrome extension you are using doesn’t interact with a server that performs scraping activity on your behalf?
To me, what “scrape in the cloud” means is far different from “scraping the cloud”. It suggests that there are process activities that may indeed be configured and managed in your browser, but which are actually performed by proxy services elsewhere.
If you can schedule a scrape and close your browser, how do you think that works? Surely, it cannot run lsolely] in your browser.
I’ve worked for a few companies that provide a variety of data harvesting technologies (import.io) and every one of them utilized servers to do the heavy lifting because browsers are (a) inefficient, (b) unable to pace themselves, (c ) unable to spread requests across multiple IPs, multiple user-agents and domains, and (d) are miserable tools where same-origin security policies come into play.
I think scraping is a fine activity and it’s wonderful to utilize these tools to acquire data. My comment was simply to point out that …
- Airtable is not likely to get into the data scraping business;
- There are lots of potential issues with scraping (technical and otherwise);
- Airtable has some pretty big competitive gaps in their solution; scraping is not going to help to close those gaps.
You’re right; “scrape in the cloud” does imply “closing my browser” and having some server execute the scraping.
My interest is simply making the Web Clipper useful and more powerful; right now it’s pretty barebones and the SimpleScraper has some great features which I’d like to see implemented in Web Clipper. Personally I care less about implementation and more about value/functionality delivered. If it preserves privacy and avoids getting blocked along the way, then those characteristics seem necessary to providing that value/functionality over time.
The current Web Clipper is severely limited in its utility, so that’s my primary concern.
You’re right; “scrape in the cloud” does imply “closing my browser” and having some server execute the scraping.
My interest is simply making the Web Clipper useful and more powerful; right now it’s pretty barebones and the SimpleScraper has some great features which I’d like to see implemented in Web Clipper. Personally I care less about implementation and more about value/functionality delivered. If it preserves privacy and avoids getting blocked along the way, then those characteristics seem necessary to providing that value/functionality over time.
The current Web Clipper is severely limited in its utility, so that’s my primary concern.
Indeed, web clipper, like many aspects of Airtable suffer from very low operating ceilings. And despite the fact that I don’t really keep tabs on all things Airtable, I can quickly name a dozen critical features that are severely limited.
In my view, web clipping doesn’t even make the top twenty most critical things in the scope of clear-headed product management.
I don’t intend to lessen the importance of web clipping to you or any other user, but I do intend to call out the deep contrasts between poorly-implemented “features” that fall into the nice to have category and deeply dependent infrastructure requirements that have been ignored for more than half a decade.
This is the difference between features that help users in a narrow scope of activity – versus – features that help people help themselves which have a vastly broader and deep-reaching impact on the ability for users solve many data management challenges, the latter of which tend to be boundless.
Airtable does some things really, really well and they’ve captivated the attention and imagination of a large segment of underserved workers who need information management solutions that are both delightfully appealing and easy to use.
How did Airtable win these customers?
Not by making it easy to import data. :winking_face: To the contrary - Airtable’s data ingestion and importing capabilities are among the weakest in their segment. Certainly, this aspect of the product must be improved, but seamless flows of data into their platform is not in their wheelhouse. As such, I must ask -
Will more users come to Airtable because it has a great web clipper?
Or …
Will vastly more users come to Airtable because it is a great data management platform – AND STAY – because they can effortlessly solve complex data management problems with advanced formula methods such as Split()?
Across this forum, I can’t recall a single instance where a user has announced their departure from Airtable because it couldn’t clip data from the web. Yet, I see many such announcements from serious business users who cannot sustain their interest going forward because the product lacked essential infrastructures that make it possible to solve data manipulation objectives.
@chrismessina @Bill.French,
Hey guys,
Mike from Simple Scraper here. Just stumbled across this discussion.
To clarify how Simple Scraper works: you can either scrape locally (no servers involved) or in the cloud (servers required), with cloud scraping having more powerful features like scheduling, as you’ve mentioned.
While not totally familiar with Airtable, I did have a quick read through the docs and it looks like a custom Simple Scraper ‘block’ may provide some of the functionality that you’re looking for, Chris.
Is it possible to build and publish custom blocks, and if not, is there any other way to pass data to Airtable?
We’ve just launched a Google Sheets integration today that instantly copies data that you’ve scraped to a Google Sheet (see ‘Saving data automatically to Google Sheets’ here: https :// simplescraper. io/guide). Airtable appears to lack an API that would support this but if there’s some equivalent method I’d gladly build an integration.
I think we’re all in agreement that moving data from A to B on the web should be as easy as possible so happy to invest time in anything that furthers that goal.
Cheers
@chrismessina @Bill.French,
Hey guys,
Mike from Simple Scraper here. Just stumbled across this discussion.
To clarify how Simple Scraper works: you can either scrape locally (no servers involved) or in the cloud (servers required), with cloud scraping having more powerful features like scheduling, as you’ve mentioned.
While not totally familiar with Airtable, I did have a quick read through the docs and it looks like a custom Simple Scraper ‘block’ may provide some of the functionality that you’re looking for, Chris.
Is it possible to build and publish custom blocks, and if not, is there any other way to pass data to Airtable?
We’ve just launched a Google Sheets integration today that instantly copies data that you’ve scraped to a Google Sheet (see ‘Saving data automatically to Google Sheets’ here: https :// simplescraper. io/guide). Airtable appears to lack an API that would support this but if there’s some equivalent method I’d gladly build an integration.
I think we’re all in agreement that moving data from A to B on the web should be as easy as possible so happy to invest time in anything that furthers that goal.
Cheers
Hi Mike, thanks for chiming in.
Yes, everyone loves data. :winking_face: The easier the better.
No. Airtable doesn’t expose this to the general user community or vendors. I recommend you contact Airtable though as a block would be one of the better approaches to providing a clean integration.
Only their REST API which means you’d have to create a boatload of infrastructure (at your server) to manage authentication, etc. (I think) Anyone, of course, could use your API and Airtable’s API to glue scraped content to a table. Airtable does support Zapier and Integromat, so that might be a pathway if your support either of those platforms.
That’s great - a good feature to have.
Thanks for the info, Bill.
Found the relevant API docs and the Javascript client so looks like it’s possible to cook up some kind of integration. Using something like Zapier is an option but directly is cleaner and simpler (for the user at least!).
To begin we can replicate what happens with the Google Sheets integration: any data scraped using Simple Scraper is instantly copied to a table. The new data can either replace or be appended to existing data.
The only limitation I can see is that it’s not possible to create tables via the API, so we’d need to create a table for the data in advance. This presents a little friction but perhaps we can make it work.
@chrismessina, how does this sound as a starting point?
Thanks for the info, Bill.
Found the relevant API docs and the Javascript client so looks like it’s possible to cook up some kind of integration. Using something like Zapier is an option but directly is cleaner and simpler (for the user at least!).
To begin we can replicate what happens with the Google Sheets integration: any data scraped using Simple Scraper is instantly copied to a table. The new data can either replace or be appended to existing data.
The only limitation I can see is that it’s not possible to create tables via the API, so we’d need to create a table for the data in advance. This presents a little friction but perhaps we can make it work.
@chrismessina, how does this sound as a starting point?
Yep. This is one of the many limitations of the current API.
I also recommend you get on the beta list to work with their forthcoming javascript implementation for building integrated Blocks.
Thanks for the info, Bill.
Found the relevant API docs and the Javascript client so looks like it’s possible to cook up some kind of integration. Using something like Zapier is an option but directly is cleaner and simpler (for the user at least!).
To begin we can replicate what happens with the Google Sheets integration: any data scraped using Simple Scraper is instantly copied to a table. The new data can either replace or be appended to existing data.
The only limitation I can see is that it’s not possible to create tables via the API, so we’d need to create a table for the data in advance. This presents a little friction but perhaps we can make it work.
@chrismessina, how does this sound as a starting point?
Awesome to have your perspective here, @Mike_ss!
Zapier would be the obvious and probably fastest path for integration, since it’s a known vendor with a bunch of patterns/infra in place, but I can’t speak on behalf of Airtable of course.
In Airtable land, I kind of think setting up a table in advance is a normal task, so not too much friction.
To give you a sense for my use case… I have a huge base w articles in which I’ve been mentioned or have given interviews, and I’d love to grab the metadata and content from them using something like your SimpleScraper. Given a list of URLs, then, SimpleScraper would go and either update or populate my base. Of course, most publishers have different HTML formatting, so it might take some work to generate the scrapers, but if those could be shared w/ the SimpleScraper community, that would greatly share the burden.
Thoughts?
Awesome to have your perspective here, @Mike_ss!
Zapier would be the obvious and probably fastest path for integration, since it’s a known vendor with a bunch of patterns/infra in place, but I can’t speak on behalf of Airtable of course.
In Airtable land, I kind of think setting up a table in advance is a normal task, so not too much friction.
To give you a sense for my use case… I have a huge base w articles in which I’ve been mentioned or have given interviews, and I’d love to grab the metadata and content from them using something like your SimpleScraper. Given a list of URLs, then, SimpleScraper would go and either update or populate my base. Of course, most publishers have different HTML formatting, so it might take some work to generate the scrapers, but if those could be shared w/ the SimpleScraper community, that would greatly share the burden.
Thoughts?
This is why scraping in general is so brittle. Yes, it will take some effort to get them working, but the maintenance required is vastly more effort because you will have to do it many times. This constant arms race will eventually push you toward a less brittle approach unless you enjoy constantly discovering the scraping processes are failing and you enjoy debugging repeatedly.
Ideally, you want to build content parsers that do not depend on tokenizing text. Instead, it’s better to employ NLP to extract entities using proven AI models. This abstracts the discovery of data away from specific content formats and makes it possible to harvest data from web sites you never planned or scripted for.
Perhaps @Mike_ss is about to include an AI architecture in SimpleScraper to make these content scraping approaches obsolete. :winking_face:
I am interested in discussing your theory of mass scraping. Do you have a minute or many?
Hi Jack, and welcome to the community!
Are you referring to my comments or from @chrismessina, or those from @Mike_ss?
Hi Jack, and welcome to the community!
Are you referring to my comments or from @chrismessina, or those from @Mike_ss?
I believe it was messina’s. Thanks for the response.
I am interested in discussing your theory of mass scraping. Do you have a minute or many?
It depends, lol. I’m about to be traveling for two weeks, so prior to February, no — I have but few minutes.
For background, I spent a bunch of time working in the 2010s on various internet formats called microformats to mark up web pages to make it easier to extract data (concept: turn every webpage into a database entry by exposing the structure using well-known semantics via CSS classes).
When I talk about “mass scraping”, I’m imagining a shared repo like Userscripts dot org (which no longer exists) where users upload their scripts for popular sites, and then collaboratively maintain them. I don’t know if this is how a service like Mercury Reader adapts to all the pages it turns into readable content, but something like that.
In an ideal world, I’d go into an editor mode and just draw boxes around the content that I want to extract from a page, and it would either figure out how to reference that content for me, and then general to other pages on the site, or somehow help me w/ the extraction process.
It depends, lol. I’m about to be traveling for two weeks, so prior to February, no — I have but few minutes.
For background, I spent a bunch of time working in the 2010s on various internet formats called microformats to mark up web pages to make it easier to extract data (concept: turn every webpage into a database entry by exposing the structure using well-known semantics via CSS classes).
When I talk about “mass scraping”, I’m imagining a shared repo like Userscripts dot org (which no longer exists) where users upload their scripts for popular sites, and then collaboratively maintain them. I don’t know if this is how a service like Mercury Reader adapts to all the pages it turns into readable content, but something like that.
In an ideal world, I’d go into an editor mode and just draw boxes around the content that I want to extract from a page, and it would either figure out how to reference that content for me, and then general to other pages on the site, or somehow help me w/ the extraction process.
Thank you for taking the time for this information. As I said, I am green to the internet (been in prison for 40 years), but I am halfway computer literate. I will try to digest what you told me and hope to hear from you when you have the time. Thanks again.
Thank you for taking the time for this information. As I said, I am green to the internet (been in prison for 40 years), but I am halfway computer literate. I will try to digest what you told me and hope to hear from you when you have the time. Thanks again.
We all are halfway literate and especially so about the web because it is always changing.
This is the promise of tools like import.io which has a free tier to gain some experience. They use some of the AI concepts I maintain are critical for building reliable and sustainable data extraction processes.
This was a common approach during the past two decades and quite effect - even today. However, the number of new content rendering techniques and the growing number of abstraction possibilities have diminished the use of CSS markers as an effective extraction method. These new layers of abstraction have inspired data seekers to look to AI as the likely pathway for transforming unstructured information into data.
It’s easy to say “AI”; much harder to put it into practical use. But, the effort to make this leap pays huge dividends. Imagine a single extraction model to pull real estate listing data from 10 prominent web platforms and all without ever modifying the extraction model when any one of the sites changes how they render specific data values. I know, it sounds too good to be true, right? But it works.
Thanks for explaining the use case some more, @chrismessina.
Similar to your idea of a shared repo, we have the concept of a “recipe store” than contains a collection of scraping configurations for various websites. As these are valuable to everybody, it’s not a problem setting these up.
I’ll dig into the Airtable API over the next couple of weeks and see what can be achieved.
@Bill.French - If the results could live up to the promise, I’d ship an AI powered Simplescraper tomorrow! Outside of some heuristics for scraping articles, this still appears to be an unsolved problem.
At the end of the day, updating a CSS selector is trivial. The question then becomes 'how do we detect and fix invalid selectors as quickly as possible?" which is a much easier problem to solve.
Will be in touch with updates soon.
Thanks for explaining the use case some more, @chrismessina.
Similar to your idea of a shared repo, we have the concept of a “recipe store” than contains a collection of scraping configurations for various websites. As these are valuable to everybody, it’s not a problem setting these up.
I’ll dig into the Airtable API over the next couple of weeks and see what can be achieved.
@Bill.French - If the results could live up to the promise, I’d ship an AI powered Simplescraper tomorrow! Outside of some heuristics for scraping articles, this still appears to be an unsolved problem.
At the end of the day, updating a CSS selector is trivial. The question then becomes 'how do we detect and fix invalid selectors as quickly as possible?" which is a much easier problem to solve.
Will be in touch with updates soon.
Indeed, this is unsolved only because no one has invested in developing models that can accurately extract data. In commoditized service offerings, vendors tend to sustain the status quo because the margins are only getting slimmer, the sure indicator disruption is likely on the near horizon.
The fact that using AI for acquiring information is still unsolved is the business opportunity - the first company that uses AI to scrape successfully will disrupt all other companies in the web-to-data segment because it will have changed the game by eliminating the brittleness, the need to craft so many scraping approaches, and the maintenance issues. Plus, it’ll expand the possibilities by adding image and PDF scraping for data, an often-used approach to thwart scraping.
Even the BoilerPipe (open-source) project has demonstrated significant improvement in scraping by peeling away shallow text artefacts using a complex algorithm. Subtle uses of AI will soon give way to pervasive use.
I see this not as an unsolved problem; rather it’s simply an unsolved solution.
Indeed, this is unsolved only because no one has invested in developing models that can accurately extract data. In commoditized service offerings, vendors tend to sustain the status quo because the margins are only getting slimmer, the sure indicator disruption is likely on the near horizon.
The fact that using AI for acquiring information is still unsolved is the business opportunity - the first company that uses AI to scrape successfully will disrupt all other companies in the web-to-data segment because it will have changed the game by eliminating the brittleness, the need to craft so many scraping approaches, and the maintenance issues. Plus, it’ll expand the possibilities by adding image and PDF scraping for data, an often-used approach to thwart scraping.
Even the BoilerPipe (open-source) project has demonstrated significant improvement in scraping by peeling away shallow text artefacts using a complex algorithm. Subtle uses of AI will soon give way to pervasive use.
I see this not as an unsolved problem; rather it’s simply an unsolved solution.
It would great to see a general purpose data extraction tool, and many companies are trying.
I think what may inhibit progress in this area is the possibility of ‘only’ achieving 90% reliability, which, while an amazing feat, is effectively no different from the brittleness inherent in today’s scraping tools.

Relevant xkcd ; )
It’s certainly worth trying though as it would be game changing.
It would great to see a general purpose data extraction tool, and many companies are trying.
I think what may inhibit progress in this area is the possibility of ‘only’ achieving 90% reliability, which, while an amazing feat, is effectively no different from the brittleness inherent in today’s scraping tools.
Relevant xkcd ; )
It’s certainly worth trying though as it would be game changing.
Perhaps true if you set aside benefits like these:
- Never configuring a scraper to get the data in the first place;
- Never having a scraper break;
- Never needing to monitor if a scraper is performing;
- Never modifying a scraper after it has fallen over;
- Never getting egg on your face when a scraper fails;
- Never spending any time analyzing the CSS patterns.
I believe that if you eliminate all of these activities and achieve 80% accuracy, the cost-benefit ratio tips well into your advantage column. You then have a chance to use additional pattern detection to remove the remaining 20% inaccurate data.
As such, even if you only eliminate 50% of the effort spent on these six activities, it is very different the brittleness inherent in today’s scraping tools.
If you have metrics concerning these six classes of profit-robbing activity, I have a hunch the math would demonstrate good reason to invest in a different technical approach.
Bear in mind, I’m certainly not a scraping expert; I just spend a lot of time revamping process automation and quite often, there are vast activities that can be eliminated while changing the underlying infrastructure.
@chrismessina - Hey Chris, a quick update on this:
We’ve been working on a custom block that allows you to easily import data into Airtable using Simplescraper. Here’s a preview of it in action:
In the demo we import data from Stackoverflow but the source could be any website that you choose - simply use the dropdown to change recipes.
Let me know if this is similar to what you had in mind?
Airtable’s custom blocks are still in preview so no ETA but wanted to keep you posted and listen to any suggestions that you may have.
Peace, Mike
@chrismessina - Hey Chris, a quick update on this:
We’ve been working on a custom block that allows you to easily import data into Airtable using Simplescraper. Here’s a preview of it in action:
In the demo we import data from Stackoverflow but the source could be any website that you choose - simply use the dropdown to change recipes.
Let me know if this is similar to what you had in mind?
Airtable’s custom blocks are still in preview so no ETA but wanted to keep you posted and listen to any suggestions that you may have.
Peace, Mike
Ooo… looks promising! So — how will this apply to arbitrary URLs?
Here’s a use case: I post a lot of stuff to Product Hunt. A lot of the apps I post are in Apple’s App Store. I’d like to be collect the app’s:
- icon
- the gallery of images, not just at the 300px size, but the 960px size
- description
- website
How could I use your block to do this?
@chrismessina - Hey Chris, a quick update on this:
We’ve been working on a custom block that allows you to easily import data into Airtable using Simplescraper. Here’s a preview of it in action:
In the demo we import data from Stackoverflow but the source could be any website that you choose - simply use the dropdown to change recipes.
Let me know if this is similar to what you had in mind?
Airtable’s custom blocks are still in preview so no ETA but wanted to keep you posted and listen to any suggestions that you may have.
Peace, Mike
This looks amazing! Any improvement with this block/script project?
I would be interested to use it for product importation on a website where I cannot use API
Mike from simple scraper. Any update for your block? This seems like a great idea.
Reply
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.