Hi,
I use Airtable to track information for film and television production.
I frequently need to sort a list of scenes by scene number, but scene numbers often have letters added to them, which screws up the sorting.
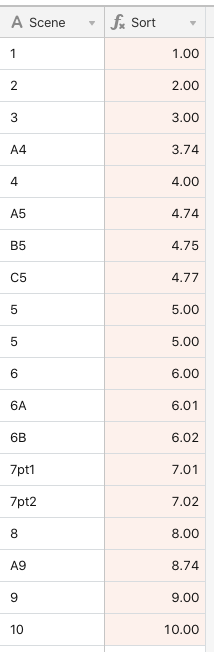
Example list, which I would want to sort in this order would be:
Sc. Number:
1
2
3
A4
4
5
A5
B5
C5
5
6
6A
6B
7pt1
7pt2
8
A9
9
10
The logic (for those unfamiliar with scene numbering) is that once a script is officially released to the crew, the scene numbers are locked. Then, when scenes are added, they add letters to indicate the scene. So if it’s a scene that comes before scene 6, it would be A6 (and if there are more than one scene added, it would be B6, C6, etc) If the scene is added after scene 6, it would be 6A, 6B, 6C, etc.
And then sometimes a scene is split up for production. Often when there is a phone call happening it’s only written as one scene, but when filming, both sides of the call are filmed, so the scene gets split into parts. Ex: 7pt1, 7pt2.
And it can be a combination of these things. So you could have a scene called A9pt1, A9pt2 A9pt3…
SO, what I’m trying to do is get this inconsistent list to sort in the correct order without manual reordering in my table.
Any thoughts?
Thanks.