Hey guys, I am trying to build a base that allows my investing firm to manage our pipeline.
This is what I have:
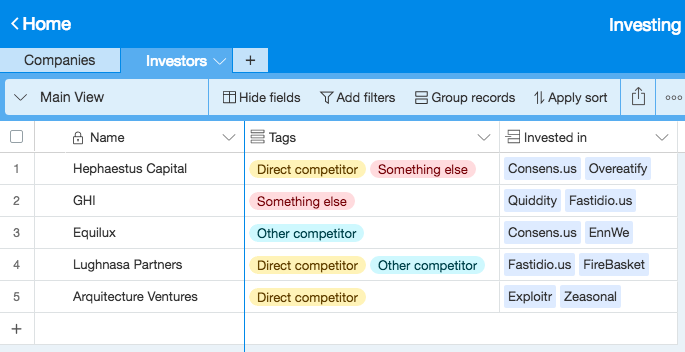
- Sheet which has Companies (under “Name”)
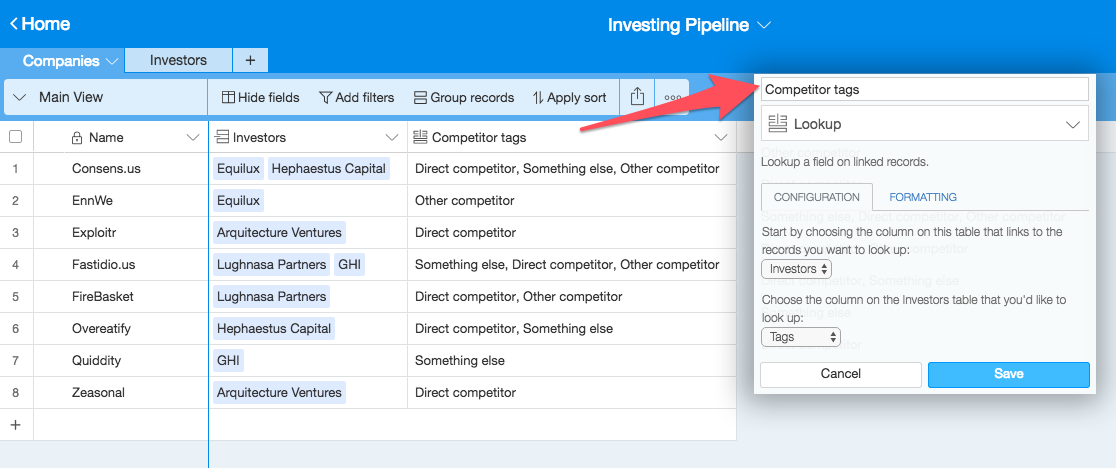
- One of the cells for each Company is “Existing Investors”–this links to another sheet (Investors) where the "Name"s are investors
- The investors are categorized into different buckets in another column – one of those categories is “Direct Competitor”
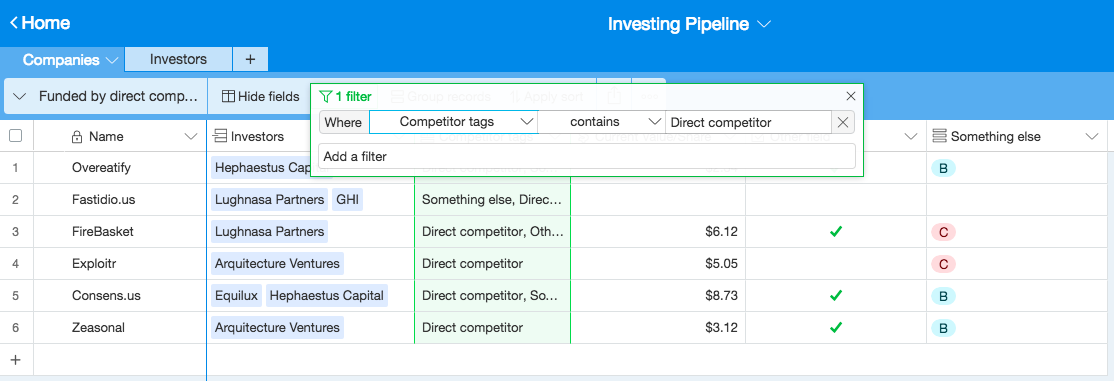
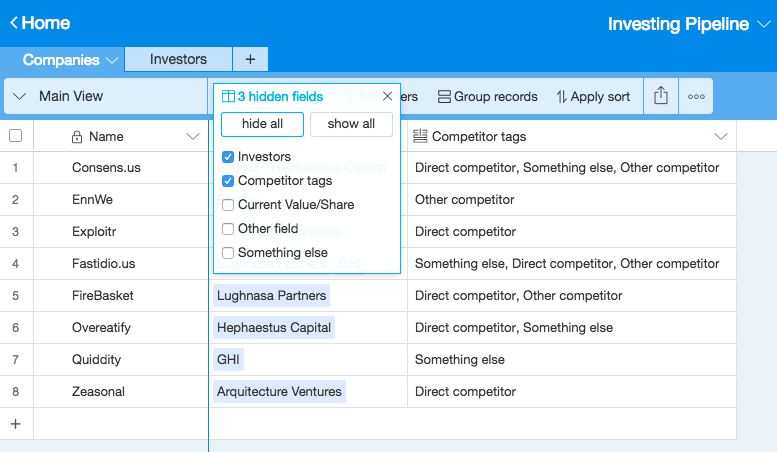
Given this information, I would like to have a different sheet where all the companies are companies which have an investor that is a Direct Competitor. Then I’d like to add more columns for additional analysis we would do that we don’t care for in the broader group of companies
Make sense? All suggestions are welcome