If you want them in two fields, use this for the Before field (replace Name with your own source field name):
LEFT(Name, FIND("/", Name) - 2)
…and this for the After field:
RIGHT(Name, LEN(Name) - FIND("/", Name) - 1)
If you want the two lines combined into one field on separate lines:
LEFT(Name, FIND("/", Name) - 2) & "\n" &
RIGHT(Name, LEN(Name) - FIND("/", Name) - 1)

If you want them in two fields, use this for the Before field (replace Name with your own source field name):
LEFT(Name, FIND("/", Name) - 2)
…and this for the After field:
RIGHT(Name, LEN(Name) - FIND("/", Name) - 1)
If you want the two lines combined into one field on separate lines:
LEFT(Name, FIND("/", Name) - 2) & "\n" &
RIGHT(Name, LEN(Name) - FIND("/", Name) - 1)
AMAZING! This totally worked. Thank You!
I want to use this same formula; however, I need to separate the string of text after and before the first number (date in this case).
Example
Field 1 (original field):
Angola 8 April 1994
Antigua and Barbuda 30 March 1987
Field 2 (First Result):
Angola
Antigua and Barbuda
Filed 3 (Second Result)
8 April 1994
30 March 1987
Can you please support with this?
Thanks
I want to use this same formula; however, I need to separate the string of text after and before the first number (date in this case).
Example
Field 1 (original field):
Angola 8 April 1994
Antigua and Barbuda 30 March 1987
Field 2 (First Result):
Angola
Antigua and Barbuda
Filed 3 (Second Result)
8 April 1994
30 March 1987
Can you please support with this?
Thanks
Are those two lines in a single record (i.e. a long text field), or are they two different records? The solution will depend on the answer to that question.
Are those two lines in a single record (i.e. a long text field), or are they two different records? The solution will depend on the answer to that question.
No, Angola 8 April 1994 would be in one line, and Antigua and Barbuda 30 March 1987 in another below it.
I have over 100 lines/records with similar information that I need to split. But all of these lines have the same sequence. “COUNTRY” & “DATE”; for example Antigua and Barbuda 30 March 1987 and then in the next line I have Angola 8 April 1994, and the line after that South Africa 25 January 2020, and so on.
No, Angola 8 April 1994 would be in one line, and Antigua and Barbuda 30 March 1987 in another below it.
I have over 100 lines/records with similar information that I need to split. But all of these lines have the same sequence. “COUNTRY” & “DATE”; for example Antigua and Barbuda 30 March 1987 and then in the next line I have Angola 8 April 1994, and the line after that South Africa 25 January 2020, and so on.
Here’s what I came up with:

Note that the {Date} field is using the default date formatting, but you can tweak it as you wish. Here’s the formula for the {Location} field:
TRIM(SUBSTITUTE(Original, DATETIME_FORMAT(Date, "D MMMM YYYY"), ""))
And the {Date} field:
DATETIME_PARSE(Original, "D MMMM YYYY")
Here’s what I came up with:
Note that the {Date} field is using the default date formatting, but you can tweak it as you wish. Here’s the formula for the {Location} field:
TRIM(SUBSTITUTE(Original, DATETIME_FORMAT(Date, "D MMMM YYYY"), ""))
And the {Date} field:
DATETIME_PARSE(Original, "D MMMM YYYY")
Hi Justin you are a SUPER STAR, thank you so much.
Here’s what I came up with:
Note that the {Date} field is using the default date formatting, but you can tweak it as you wish. Here’s the formula for the {Location} field:
TRIM(SUBSTITUTE(Original, DATETIME_FORMAT(Date, "D MMMM YYYY"), ""))
And the {Date} field:
DATETIME_PARSE(Original, "D MMMM YYYY")
Hello Justin, I have similar issue.
From cells with text followed with (number) I would like to extract just the number value to be able to sum in a new column.
I show you are very good in this so please help me!
See the example of what Im looking to do it.
Thank you very much!

Hello Justin, I have similar issue.
From cells with text followed with (number) I would like to extract just the number value to be able to sum in a new column.
I show you are very good in this so please help me!
See the example of what Im looking to do it.
Thank you very much!
A couple questions come to mind:
- Are there always going to be two numbers to extract?
- Are the numbers always going to be single digits (i.e. less than 10)?
I can think of a couple ways to go about this, but it will depend on the predictability of certain patterns in the data, which is why the answers to these questions are important.
Hi Justin,
Thanks for your quick replay.
No, for example this could be the largest hypothetical example: FICHAR (7), INTERESANTE (11), SEGUIR EVOLUCION (8), SEGUIR JOVEN (3), FIDELIZAR 2A (4), FIDELIZAR 2B (13), FIDELIZAR 3 (8), DESCARTAR (1), –SIN VALORACION– (1).
No. could be 9 & 11 for example.
Hi Justin,
Thanks for your quick replay.
No, for example this could be the largest hypothetical example: FICHAR (7), INTERESANTE (11), SEGUIR EVOLUCION (8), SEGUIR JOVEN (3), FIDELIZAR 2A (4), FIDELIZAR 2B (13), FIDELIZAR 3 (8), DESCARTAR (1), –SIN VALORACION– (1).
No. could be 9 & 11 for example.
Where are the numbers coming from? Are they being added to that string via a formula elsewhere in the base? I’m just wondering if it’s possible to extract the numbers before they get put into the massive string.
Also, what type of field is this string in? Is it just a single line text, or maybe a lookup/rollup field?
Where are the numbers coming from? Are they being added to that string via a formula elsewhere in the base? I’m just wondering if it’s possible to extract the numbers before they get put into the massive string.
Also, what type of field is this string in? Is it just a single line text, or maybe a lookup/rollup field?
They are imported from another data base. The string is not a formula it is a single text. That info is already send it from the provider like this.
They are imported from another data base. The string is not a formula it is a single text. That info is already send it from the provider like this.
This turned out to be a lot trickier than I initially expected, but I got something that works.
I first added a field that spreads out each item using large blocks of spaces. In my test, I found that a fairly high number was required, so I went with 50. I also removed the parentheses, as those were messing up the final calculation. I put the raw text in a field named {Source}, but obviously you can rename this as needed for your base.
SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(Source, ",", REPT(" ", 50)), "(", ""), ")", "")
I named this formula field {Spread}. Using your longest example, it gave me this (looking at the expanded view of the field:

I then extracted each section in a separate formula field. The field names were {Item 1}, {Item 2}, {Item 3}, etc. The formulas are similar, but each one depends on what was extracted by the one before it. This technique takes advantage of the fact that the MID() function doesn’t care if you tell it to extract part of a string that doesn’t exist (e.g. start at character 250 of a string that’s only 100 characters long).
Item 1
TRIM(MID(Spread, 1, 50))
Item 2
TRIM(MID(Spread, 50 + LEN({Item 1}), 50))
Item 3
TRIM(MID(Spread, 100 + LEN({Item 1} & {Item 2}), 50))
Item 4
TRIM(MID(Spread, 150 + LEN({Item 1} & {Item 2} & {Item 3}), 50))
Item 5
TRIM(MID(Spread, 200 + LEN({Item 1} & {Item 2} & {Item 3} & {Item 4}), 50))
Item 6
TRIM(MID(Spread, 250 + LEN({Item 1} & {Item 2} & {Item 3} & {Item 4} & {Item 5}), 50))
Item 7
TRIM(MID(Spread, 300 + LEN({Item 1} & {Item 2} & {Item 3} & {Item 4} & {Item 5} & {Item 6}), 50))
Item 8
TRIM(MID(Spread, 350 + LEN({Item 1} & {Item 2} & {Item 3} & {Item 4} & {Item 5} & {Item 6} & {Item 7}), 50))
Item 9
TRIM(MID(Spread, 400 + LEN({Item 1} & {Item 2} & {Item 3} & {Item 4} & {Item 5} & {Item 6} & {Item 7} & {Item 8}), 50))
Finally, there’s the {Total} formula field that adds up the respective numbers from each section:
SUM(
IF({Item 1}, VALUE(RIGHT({Item 1}, 2))),
IF({Item 2}, VALUE(RIGHT({Item 2}, 2))),
IF({Item 3}, VALUE(RIGHT({Item 3}, 2))),
IF({Item 4}, VALUE(RIGHT({Item 4}, 2))),
IF({Item 5}, VALUE(RIGHT({Item 5}, 2))),
IF({Item 6}, VALUE(RIGHT({Item 6}, 2))),
IF({Item 7}, VALUE(RIGHT({Item 7}, 2))),
IF({Item 8}, VALUE(RIGHT({Item 8}, 2))),
IF({Item 9}, VALUE(RIGHT({Item 9}, 2)))
)
Here’s the output from my test:

This turned out to be a lot trickier than I initially expected, but I got something that works.
I first added a field that spreads out each item using large blocks of spaces. In my test, I found that a fairly high number was required, so I went with 50. I also removed the parentheses, as those were messing up the final calculation. I put the raw text in a field named {Source}, but obviously you can rename this as needed for your base.
SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(Source, ",", REPT(" ", 50)), "(", ""), ")", "")
I named this formula field {Spread}. Using your longest example, it gave me this (looking at the expanded view of the field:
I then extracted each section in a separate formula field. The field names were {Item 1}, {Item 2}, {Item 3}, etc. The formulas are similar, but each one depends on what was extracted by the one before it. This technique takes advantage of the fact that the MID() function doesn’t care if you tell it to extract part of a string that doesn’t exist (e.g. start at character 250 of a string that’s only 100 characters long).
Item 1
TRIM(MID(Spread, 1, 50))
Item 2
TRIM(MID(Spread, 50 + LEN({Item 1}), 50))
Item 3
TRIM(MID(Spread, 100 + LEN({Item 1} & {Item 2}), 50))
Item 4
TRIM(MID(Spread, 150 + LEN({Item 1} & {Item 2} & {Item 3}), 50))
Item 5
TRIM(MID(Spread, 200 + LEN({Item 1} & {Item 2} & {Item 3} & {Item 4}), 50))
Item 6
TRIM(MID(Spread, 250 + LEN({Item 1} & {Item 2} & {Item 3} & {Item 4} & {Item 5}), 50))
Item 7
TRIM(MID(Spread, 300 + LEN({Item 1} & {Item 2} & {Item 3} & {Item 4} & {Item 5} & {Item 6}), 50))
Item 8
TRIM(MID(Spread, 350 + LEN({Item 1} & {Item 2} & {Item 3} & {Item 4} & {Item 5} & {Item 6} & {Item 7}), 50))
Item 9
TRIM(MID(Spread, 400 + LEN({Item 1} & {Item 2} & {Item 3} & {Item 4} & {Item 5} & {Item 6} & {Item 7} & {Item 8}), 50))
Finally, there’s the {Total} formula field that adds up the respective numbers from each section:
SUM(
IF({Item 1}, VALUE(RIGHT({Item 1}, 2))),
IF({Item 2}, VALUE(RIGHT({Item 2}, 2))),
IF({Item 3}, VALUE(RIGHT({Item 3}, 2))),
IF({Item 4}, VALUE(RIGHT({Item 4}, 2))),
IF({Item 5}, VALUE(RIGHT({Item 5}, 2))),
IF({Item 6}, VALUE(RIGHT({Item 6}, 2))),
IF({Item 7}, VALUE(RIGHT({Item 7}, 2))),
IF({Item 8}, VALUE(RIGHT({Item 8}, 2))),
IF({Item 9}, VALUE(RIGHT({Item 9}, 2)))
)
Here’s the output from my test:
SUPERB Justin!!!
It works perfectly!!! Many thanks!
Hello guys!
i am having a bit of trouble starting my project on airtable so i hope you can help me…
I am trying to webscrap different data from companies t the issue i have is that i wanted a table base with the companies but also a linked one with all representants of that company listed in that table.
The problem i have is that i get a list of every representants name, date of birth etc, that is filled in a single field.
Usually i enter a SIREN code that gets my Zap webhook to extract the informations i want, with all the representants of the company, but those are most of the time several. For exemple for one company i can have 5 representants, but i am having trouble to get airtable to create 5 different lines for each one so i can webscrap in that table more information about them (date of birth for exemple…).
I’m sorry for my english i am from France and probably really bad at that, i hope that you can help me in some way!
Hello guys!
i am having a bit of trouble starting my project on airtable so i hope you can help me…
I am trying to webscrap different data from companies t the issue i have is that i wanted a table base with the companies but also a linked one with all representants of that company listed in that table.
The problem i have is that i get a list of every representants name, date of birth etc, that is filled in a single field.
Usually i enter a SIREN code that gets my Zap webhook to extract the informations i want, with all the representants of the company, but those are most of the time several. For exemple for one company i can have 5 representants, but i am having trouble to get airtable to create 5 different lines for each one so i can webscrap in that table more information about them (date of birth for exemple…).
I’m sorry for my english i am from France and probably really bad at that, i hope that you can help me in some way!
Welcome to the community, @Stive_Fernandes_Alve! :grinning_face_with_big_eyes: First off, your question is only marginally related to the original post that started this thread (as are some others that have kept this thread alive since it was kicked off in May 2019). Unless the issue you’re encountering is virtually identical to one you’ve found in another thread, it’s better to start a new thread than add to an existing one.
That aside, this is technically doable with Airtable formulas, but the required data extraction is so complex that building such a system wouldn’t be a major effort (and frankly not one that I’d enjoy tackling, even though I love a good challenge). It would be much easier to process this data and create the relevant records by parsing it with a script. Zapier does have a scripting module that you can insert into a zap, but my Zapier knowledge is cursory at best, so I’m not certain if this could be set up later to add multiple records from the extracted data.
My inclination would be to send the full combined data to Airtable as a record in a table that’s specifically made to process this stuff. That new record could trigger an automation that runs a script to parse it and make the necessary records in your staff table. Just be aware that this can only be done if your base is in a Pro-plan workspace or higher.
Hi there,
this is my first post, so please be kind! 
I used the original formula and solution to create a Firstname Field and Lastname Field from a Fullname field.
All is well as long as the Fullname field is just 2 words, like Jane Doe. As soon as the Fullname field has e.g. Jane Mary Doe I get Firstname = Jane and Lastname = Mary Doe.
Essentially I am looking for a workaround for the SPLIT() function in Google Sheets.
Thanks for your help!
Hi there,
this is my first post, so please be kind!
I used the original formula and solution to create a Firstname Field and Lastname Field from a Fullname field.
All is well as long as the Fullname field is just 2 words, like Jane Doe. As soon as the Fullname field has e.g. Jane Mary Doe I get Firstname = Jane and Lastname = Mary Doe.
Essentially I am looking for a workaround for the SPLIT() function in Google Sheets.
Thanks for your help!
Welcome to the community, @Steffen_Giebeler! :grinning_face_with_big_eyes: Here’s a version that uses a combination of old and new techniques.
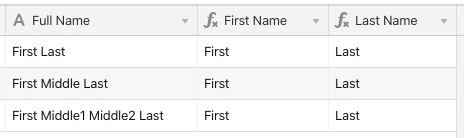
For the {First Name} field, I’m using a variation of the original formula I posted a couple of years ago:
IF({Full Name}, LEFT({Full Name}, FIND(" ", {Full Name}) - 1))
For {Last Name}, I’m using a regular expression to find all names except the last one and blank them out, leaving only the last name (provided that the last name doesn’t have a trailing space after it):
IF({Full Name}, REGEX_REPLACE({Full Name}, ".+\\s", ""))
Welcome to the community, @Steffen_Giebeler! :grinning_face_with_big_eyes: Here’s a version that uses a combination of old and new techniques.
For the {First Name} field, I’m using a variation of the original formula I posted a couple of years ago:
IF({Full Name}, LEFT({Full Name}, FIND(" ", {Full Name}) - 1))
For {Last Name}, I’m using a regular expression to find all names except the last one and blank them out, leaving only the last name (provided that the last name doesn’t have a trailing space after it):
IF({Full Name}, REGEX_REPLACE({Full Name}, ".+\\s", ""))
As an update, here’s another way to extract the first name using a regular expression (thanks to @ScottWorld for helping me troubleshoot the syntax; this stuff is so finicky!):
IF({Full Name}, TRIM(REGEX_EXTRACT({Full Name}, ".*?\\s")))
Welcome to the community, @Steffen_Giebeler! :grinning_face_with_big_eyes: Here’s a version that uses a combination of old and new techniques.
For the {First Name} field, I’m using a variation of the original formula I posted a couple of years ago:
IF({Full Name}, LEFT({Full Name}, FIND(" ", {Full Name}) - 1))
For {Last Name}, I’m using a regular expression to find all names except the last one and blank them out, leaving only the last name (provided that the last name doesn’t have a trailing space after it):
IF({Full Name}, REGEX_REPLACE({Full Name}, ".+\\s", ""))
Hi Justin,
thanks so much for this. Works like a charm!
Hi Justin ,
I have similar kind of problem , hope you can help me also.
I am trying to extract particular Strings followed by word. for e.g
This is stored as long text.
Date Wed, 31 Mar 2021 11:45:50 PDT Build Version 1.1.22 User ID ABC Issue Reported* this is for testing Actions Tried -------------Networking-----
I would need to Extract values followed by Date , USER ID and Issue Reported Fields. Length of User id value or the Issue reported may differ so I would like to take whole value followed by these keywords. MID will give me the value, starting value will be same always but as I dont know the end of String so dont know how to proceed with that.
Any help on the same would be Highly Appreciated
Note : Values might not be on the same line as shown above but there can be spaces between the field and Value
Hi Justin ,
I have similar kind of problem , hope you can help me also.
I am trying to extract particular Strings followed by word. for e.g
This is stored as long text.
Date Wed, 31 Mar 2021 11:45:50 PDT Build Version 1.1.22 User ID ABC Issue Reported* this is for testing Actions Tried -------------Networking-----
I would need to Extract values followed by Date , USER ID and Issue Reported Fields. Length of User id value or the Issue reported may differ so I would like to take whole value followed by these keywords. MID will give me the value, starting value will be same always but as I dont know the end of String so dont know how to proceed with that.
Any help on the same would be Highly Appreciated
Note : Values might not be on the same line as shown above but there can be spaces between the field and Value
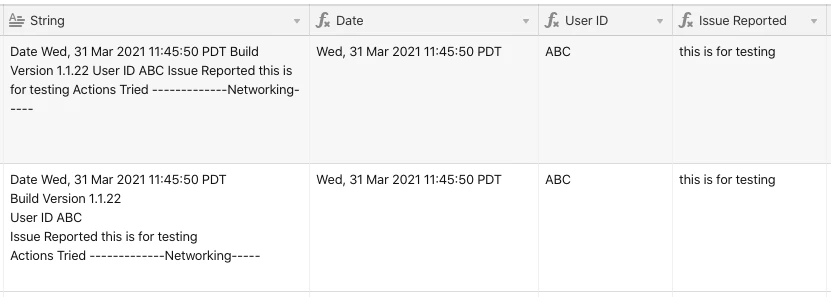
@Prabhjot_Singh_Gill I made three regular expressions. Here’s the one to grab the date:
IF(String, TRIM(REGEX_EXTRACT(String, "(?:Date\\s)(.*)(?:\\sBuild.*)")))
Now the user ID:
IF(String, TRIM(REGEX_EXTRACT(String, "(?:.*User ID)(.*)(?:\\sIssue Reported.*)")))
And the issue reported:
IF(String, TRIM(REGEX_EXTRACT(String, "(?:.*Issue Reported)(.*)(?:\\sActions Tried.*)")))
These will work whether everything is on a single line (top record), or split onto separate lines (bottom record).
The way these work is by using groups. Groups are wrapped in parentheses, and each group is matched in order. When a group begins with ?: it means to find the group, but ignore its contents when returning the result. In the end, each field finds (and ignores) just enough material to locate when a given item begins, and captures captures everything from there to the start of the next specific group, which is also ignored. The end result is trimmed to eliminate whitespace.
@Prabhjot_Singh_Gill I made three regular expressions. Here’s the one to grab the date:
IF(String, TRIM(REGEX_EXTRACT(String, "(?:Date\\s)(.*)(?:\\sBuild.*)")))
Now the user ID:
IF(String, TRIM(REGEX_EXTRACT(String, "(?:.*User ID)(.*)(?:\\sIssue Reported.*)")))
And the issue reported:
IF(String, TRIM(REGEX_EXTRACT(String, "(?:.*Issue Reported)(.*)(?:\\sActions Tried.*)")))
These will work whether everything is on a single line (top record), or split onto separate lines (bottom record).
The way these work is by using groups. Groups are wrapped in parentheses, and each group is matched in order. When a group begins with ?: it means to find the group, but ignore its contents when returning the result. In the end, each field finds (and ignores) just enough material to locate when a given item begins, and captures captures everything from there to the start of the next specific group, which is also ignored. The end result is trimmed to eliminate whitespace.
Thank alot @Justin_Barrett , I took me somewhere but now I got an idea on how it works so I will play around with it more. Really appreciate your help on the same .
If you want them in two fields, use this for the Before field (replace Name with your own source field name):
LEFT(Name, FIND("/", Name) - 2)
…and this for the After field:
RIGHT(Name, LEN(Name) - FIND("/", Name) - 1)
If you want the two lines combined into one field on separate lines:
LEFT(Name, FIND("/", Name) - 2) & "\n" &
RIGHT(Name, LEN(Name) - FIND("/", Name) - 1)
The second half of this formula, the RIGHT() portion, solved my need for an Airtable split string formula. Thank you so very much!
Kia ora from New Zealand @Justin_Barrett,
Reading through the thread you sound like the kind of human that may be able to help me out, I am looking to split each of the lines from a long text field into a separate short text field?
eg
Long Text Field:
This is the first line
This is the second Line
This is the third
Split out into:
Short Text Field:
This is the first line
Short Text Field:
This is the second line
Short Text Field:
This is the third line
Any thoughts?
