Welcome to the community, @Daley_Maasz! :grinning_face_with_big_eyes: This is doable, but the three target fields will be formula fields, not single line text fields. Formulas can only dictate their own output; they can’t control the contents of other fields.
Here’s the setup in action, followed by the formulas:
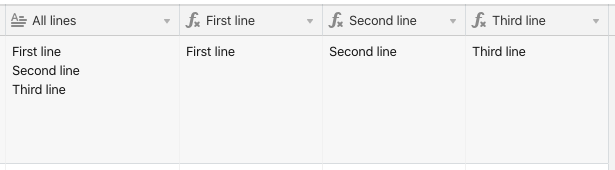
First line…
REGEX_EXTRACT({All lines}, "(.*)(?:\n.*)")
Second line…
REGEX_EXTRACT({All lines}, "(?:.*\n)(.*)(?:\n.*)")
Third line…
REGEX_EXTRACT({All lines}, "(?:.*\n){2}(.*)")
Thanks @Justin_Barrett - just an update that I had to apply to below changes for it to work in my case:
Second line extract:
REGEX_EXTRACT({parsed_delivery-address}, “(?:.\n)(.)”)
Third line extract:
REGEX_EXTRACT({parsed_delivery-address}, “(?:.\n)(?:.\n)(.*)”)
And I am now playing around with it being able to extract a fourth line but hitting issues so will update once I am able to get it working.
Not sure what was going on but the fourth line extract answer did indeed follow the same logic:
REGEX_EXTRACT({parsed_delivery-address}, “(?:.\n)(?:.\n)(?:.\n)(.)”)
@Justin_Barrett any ideas on how to build these into ‘IF’ statements that would would return a blank field entry in place of the ‘#ERROR!’ when the regex returns false?
@Daley_Maasz The formulas I wrote above were copied directly from the fields where I tested them, so it’s odd that the second and third ones didn’t work for you. Were you copying them to your formula fields, or retyping them manually? If it’s the latter, you might have typed something incorrectly. If you copied them, then there must be something with your base setup that wouldn’t work with them. Your comment about extracting a fourth line makes me think that the number of lines to extract isn’t always consistent. Is that the case?
@Justin_Barrett That is correct, it can be anywhere from 2 to 4 lines of text.
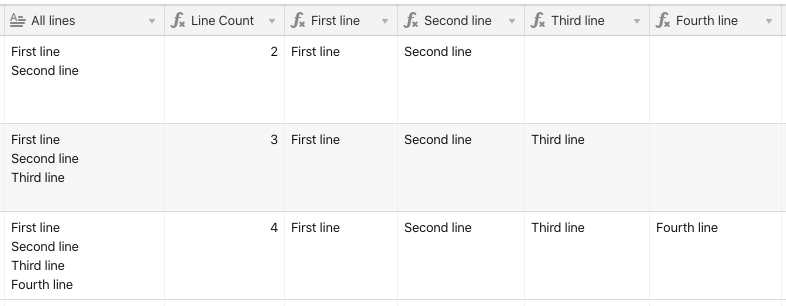
@Daley_Maasz Thanks for the clarification. This changes the setup slightly, but the core of what I wrote before still remains. First I suggest making a formula field named {Line Count} using this formula:
IF({All lines}, LEN({All lines}) - LEN(SUBSTITUTE({All lines}, "\n", "")) + 1)
The other fields will use this to determine whether or not to extract a given line. Here are the rest of the formulas.
First line
IF({Line Count}, REGEX_EXTRACT({All lines}, "(.*)(?:\n.*)"))
Second line
IF({Line Count} > 1, REGEX_EXTRACT({All lines}, "(?:.*\n)(.*)"))
Third line
IF({Line Count} > 2, REGEX_EXTRACT({All lines}, "(?:.*\n){2}(.*)"))
Fourth line
IF({Line Count} > 3, REGEX_EXTRACT({All lines}, "(?:.*\n){3}(.*)"))
@Justin_Barrett It worked perfectly, thank you.
Hello,
I have a similar problem, but I can’t seem to find the answer in this thread.
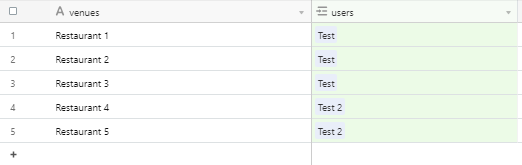
I would like to separate into different records, strings of text separated by commas.
! 
The tricky thing is, I don’t know how many “restaurants” there will be ! Does anyone have a solution ?
Also, I would like to add those “restaurants” records (split into separate strings of text) in another table (with an automation), and link it to the previous table with the strings of text.
Thank you for your help!!
Hi Mathilde,
do you know the maximum number of restaurants that can be in the field?
What do you actually want is to separate each restaurant in a separated value new field (field = new column) ?
Could you give an extra explanation for the automation?
Thanks
Hi Mathilde,
do you know the maximum number of restaurants that can be in the field?
What do you actually want is to separate each restaurant in a separated value new field (field = new column) ?
Could you give an extra explanation for the automation?
Thanks
Hi Dimitris,
Actually I don’t know the maximum because it will depend on our client profiles, but I can imagine that we won’t have over 20 restaurants in a single string
Exactly, I would like to create a record for each restaurant in another table, each of them linked to the group of restaurants they belong to !
So :
1- Separate strings into different restaurants records
2- Link each restaurant records to the first table
This is the result I am looking for :
Thank you very much!
Welcome to the Airtable community!
Airtable does not have a split function. You can look into this thread for one method. However, since your end goal is more linked records, and not the actual contents of the different fields, you may want to look into having a script to do all of the processing from splitting the text string to making the linked records.
Hi again 
to split the filed with restaurants the solution is like above, to split based in comma existence and position in the mother field for every next restaurant.
As about the automation you are looking for I didn’t get again what you want to do because I can not understand the process you follow. If you want feel free to text me a private message for further explanation.
Welcome to the Airtable community!
Airtable does not have a split function. You can look into this thread for one method. However, since your end goal is more linked records, and not the actual contents of the different fields, you may want to look into having a script to do all of the processing from splitting the text string to making the linked records.
Hi kuovonne,
Thanks for your reply ! Would you have an idea of what the script could be ? Thank you!!
Hi kuovonne,
Thanks for your reply ! Would you have an idea of what the script could be ? Thank you!!
If you choose to go the scripting route, I recommend a custom script. Situations like this tend to have enough unique details that a pre-built script (if you can find one) rarely does everything that you want.
If you know how to code the documentation is excellent.
If you do not know how to code or do not want to learn to code, you can hire someone to write a custom script for you. There are several custom script writers on these forums, including myself.
Welcome to the community, @Steffen_Giebeler! :grinning_face_with_big_eyes: Here’s a version that uses a combination of old and new techniques.
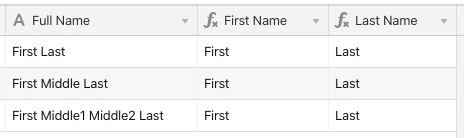
For the {First Name} field, I’m using a variation of the original formula I posted a couple of years ago:
IF({Full Name}, LEFT({Full Name}, FIND(" ", {Full Name}) - 1))
For {Last Name}, I’m using a regular expression to find all names except the last one and blank them out, leaving only the last name (provided that the last name doesn’t have a trailing space after it):
IF({Full Name}, REGEX_REPLACE({Full Name}, ".+\\s", ""))
This is working so good with First and Last Name, but, i’m wondering… how about the “Middle2” in your table. Im on a Latinamerican country and We Usually name like this (example name):
Carlos Roberto Flores González
How can i extract “Flores” from it?
Thanks in advance.
This is working so good with First and Last Name, but, i’m wondering… how about the “Middle2” in your table. Im on a Latinamerican country and We Usually name like this (example name):
Carlos Roberto Flores González
How can i extract “Flores” from it?
Thanks in advance.
Welcome to the community, @Rodrigo_Flores! :grinning_face_with_big_eyes: This will extract the next-to-last item from a string (using spaces for separation):
IF(Name, REGEX_EXTRACT(Name, "(R^ ]+) (e^ ]+)$"))

Welcome to the community, @Rodrigo_Flores! :grinning_face_with_big_eyes: This will extract the next-to-last item from a string (using spaces for separation):
IF(Name, REGEX_EXTRACT(Name, "([^ ]+) ([^ ]+)$"))
Wow, it worked! :winking_face: many thanks Justin. Just to be aware, how can i study the logic of those functions “(�^ ]+) ( ^ ]+)$”, or, what’s the logic behind that… :smiling_face_with_sunglasses: you rock!
thanks!
Wow, it worked! :winking_face: many thanks Justin. Just to be aware, how can i study the logic of those functions “(�^ ]+) ( ^ ]+)$”, or, what’s the logic behind that… :smiling_face_with_sunglasses: you rock!
thanks!
First off, the $ at the end anchors the pattern to the end of the string. Without that, the regex engine would search for a match at the start of the string.
Parentheses are used to define search groups. In the expression that I wrote, there are two matching groups separated by a space, meaning that both groups and the separating space would need to be matched for anything to be returned.
Square braces are wrapped around collections of individual characters that should be matched. However, the caret ^ character at the front tells the regex engine to not match any of the following characters. In this case, we want to not match a space.
The + token after the square brace collection says to match the preceding token—any non-space character—one or more times.
Taken altogether, this collection—(t^ ]+)—will match any non-space character one or more times, effectively selecting a single word. (Note: There is a separate \w token for specifically selecting “word” characters, but it’s very narrowly-focused in the characters that it matches. The version that I’m using is more broad, literally matches anything that’s not a space.)
Taking everything into account, the full expression says, “Find the pattern WORD-SPACE-WORD at the end of the string.”
With that in mind, we now hit an interesting bit of idiosyncratic behavior: Airtable’s regex implementation only returns the contents of the first defined group. So even though we’re telling the regex engine to find two words separated by a space, only the first word is actually returned, giving us the second-to-last word in the string.
To learn more, I recommend bookmarking a site like regex101.com (where you’ll need to select the Golang “flavor” to most-closely match the regex engine that Airtable uses), and just playing around.
First off, the $ at the end anchors the pattern to the end of the string. Without that, the regex engine would search for a match at the start of the string.
Parentheses are used to define search groups. In the expression that I wrote, there are two matching groups separated by a space, meaning that both groups and the separating space would need to be matched for anything to be returned.
Square braces are wrapped around collections of individual characters that should be matched. However, the caret ^ character at the front tells the regex engine to not match any of the following characters. In this case, we want to not match a space.
The + token after the square brace collection says to match the preceding token—any non-space character—one or more times.
Taken altogether, this collection—(c^ ]+)—will match any non-space character one or more times, effectively selecting a single word. (Note: There is a separate \w token for specifically selecting “word” characters, but it’s very narrowly-focused in the characters that it matches. The version that I’m using is more broad, literally matches anything that’s not a space.)
Taking everything into account, the full expression says, “Find the pattern WORD-SPACE-WORD at the end of the string.”
With that in mind, we now hit an interesting bit of idiosyncratic behavior: Airtable’s regex implementation only returns the contents of the first defined group. So even though we’re telling the regex engine to find two words separated by a space, only the first word is actually returned, giving us the second-to-last word in the string.
To learn more, I recommend bookmarking a site like regex101.com (where you’ll need to select the Golang “flavor” to most-closely match the regex engine that Airtable uses), and just playing around.
Thank you Justin, do me a favor… take care, you’re awesome! 
This conversation seems related to my current issue, but I’m looking for something that splits text out to columns from a comma separated list of kids’ first names in one field. Sometimes there are no kids sometime one, two, and even one instance of 7 kids. So I want to have at least seven new fields populated with the text between commas: Child FN 1, Child FN 2, Child FN 3, Child FN 4, Child FN 5, Child FN 6, Child FN 7. Any suggestions?
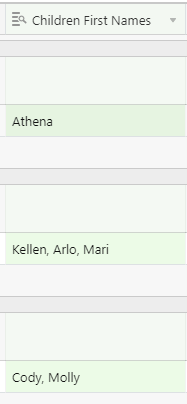
This conversation seems related to my current issue, but I’m looking for something that splits text out to columns from a comma separated list of kids’ first names in one field. Sometimes there are no kids sometime one, two, and even one instance of 7 kids. So I want to have at least seven new fields populated with the text between commas: Child FN 1, Child FN 2, Child FN 3, Child FN 4, Child FN 5, Child FN 6, Child FN 7. Any suggestions?
@Justin_Barrett, I’m curious if you had some suggestions. Thanks.
@Justin_Barrett, I’m curious if you had some suggestions. Thanks.
Welcome to the community, @ACRA_Data! :grinning_face_with_big_eyes: This can be solved using a variation of the multi-line extraction technique from above.
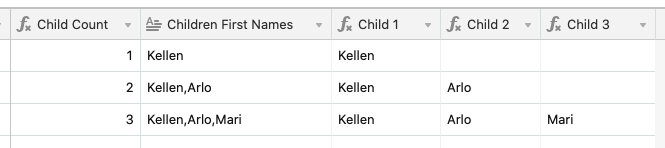
First, add a {Child Count} field. The method above uses a formula to count lines, but because the children in your base are in linked records, you can use a count field that counts the links.
For {Child 1}, the formula could be this:
IF({Child Count}, REGEX_EXTRACT({Children First Names} & "", " ^,]*"))
{Child 2} would be this:
IF({Child Count} > 1, REGEX_EXTRACT({Children First Names} & "", "(?:?^,]*,)()^,]*)"))
{Child 3} would be this:
IF({Child Count} > 2, REGEX_EXTRACT({Children First Names} & "", "(?:?^,]*,){2}(}^,]*)"))
The formulas for {Child 4} through {Child 7} would continue the pattern begun in {Child 3}. With each successive formula, you would increase the following numbers by one:
- The number in the comparison against
{Child Count}
- The number in curly brackets in the middle of the regular expression
Welcome to the community, @ACRA_Data! :grinning_face_with_big_eyes: This can be solved using a variation of the multi-line extraction technique from above.
First, add a {Child Count} field. The method above uses a formula to count lines, but because the children in your base are in linked records, you can use a count field that counts the links.
For {Child 1}, the formula could be this:
IF({Child Count}, REGEX_EXTRACT({Children First Names} & "", "[^,]*"))
{Child 2} would be this:
IF({Child Count} > 1, REGEX_EXTRACT({Children First Names} & "", "(?:[^,]*,)([^,]*)"))
{Child 3} would be this:
IF({Child Count} > 2, REGEX_EXTRACT({Children First Names} & "", "(?:[^,]*,){2}([^,]*)"))
The formulas for {Child 4} through {Child 7} would continue the pattern begun in {Child 3}. With each successive formula, you would increase the following numbers by one:
- The number in the comparison against
{Child Count}
- The number in curly brackets in the middle of the regular expression
Thanks @Justin_Barrett! This is super helpful!
Hello All,
I’m new to this community and appreciate all the discussion thus far. But I don’t see a solution to my particular problem quite yet.
I’m trying to do something similar to @ACRA_Data, but rather than having the first names in separate columns, I would like them to be in the same column as a multiple select field, rather than a single text field. I think I need to change something in the REGEX_EXTRACT function, but can’t figure it out.
The column on the left in the image below shows you what I have, and the column on the right is what I am working towards. The column on the left can have words separated by commas ranging from 1 to 10. Any help is very much appreciated.

Hello All,
I’m new to this community and appreciate all the discussion thus far. But I don’t see a solution to my particular problem quite yet.
I’m trying to do something similar to @ACRA_Data, but rather than having the first names in separate columns, I would like them to be in the same column as a multiple select field, rather than a single text field. I think I need to change something in the REGEX_EXTRACT function, but can’t figure it out.
The column on the left in the image below shows you what I have, and the column on the right is what I am working towards. The column on the left can have words separated by commas ranging from 1 to 10. Any help is very much appreciated.
Welcome to the community, @Riddhi_Mehta-Neugeba! :grinning_face_with_big_eyes:
The only thing that the REGEX_EXTRACT() function can do is extract text. It can’t control how that text is presented. For that matter, there’s nothing that any formula function can do to make the formula output look like those colored “pills” that you see in single- and multiple-select fields.
You didn’t indicate whether this is a one-time need or something that will need to be repeated on a regular basis. If it’s a one-time thing, it’s pretty easy.
- Duplicate your field, making sure to choose “Duplicate Cells”
- Change the field type of the duplicate field to single line text.
- Change the field type to multiple-select. Airtable will automatically create new items based on the comma separation in the text.
If this is a recurring conversion need, you could use an automation. Before setting this up, add a multiple-select field, but create it with no options. Those will be handled automatically by the automation. Assuming for this example that your original field is named {Options}, I’ll call the multiple-select field {Options Converted}.
Set the automation up as follows:
- Trigger: When a record is updated. Specifically, only look for changes in the
{Options} field.
- The only action you’ll need is an “Update record” action. Update the triggering record to copy the name of the selected “Options” choice into the “Options Converted” field.
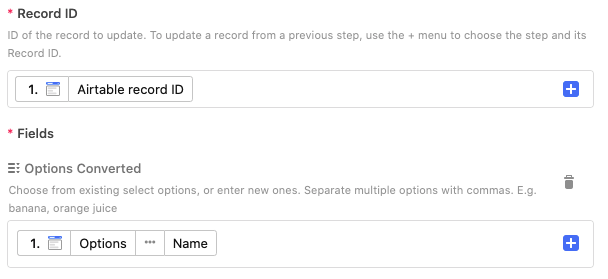
Notice how the helper text under “Options Converted” says, “Separate multiple options with commas”. By feeding it the name of the selection from the {Options} field—which contains comma-separated items—it will automatically create new entries based on those items. If the items already exist, it will select them and not add duplicates.
Here’s a demo of how that works. In this case, I’m manually choosing a selection from {Options}, but the same behavior would work if the records are being created via a form.