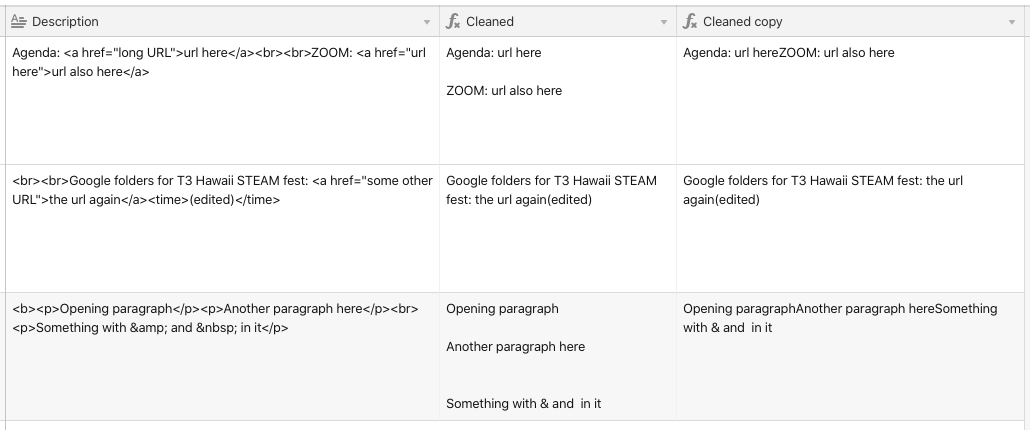
Welcome to the community, @Madara_Mason! :grinning_face_with_big_eyes: I recommend making a formula field and using this to create a clean version of the data:
TRIM(REGEX_REPLACE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(Description, "&", "&"), " ", ""), "</p>", "\n\n"), "<br>", "\n"), "<[^>]*>", ""))
That formula directly replaces certain tags with equivalent symbols (newlines, ampersands, etc.), and then REGEX_REPLACE() bulk-replaces any other HTML tags with nothing, followed by a final trim to clean up things like that second example where it starts with line breaks (which are newlines by that point).
If you don’t want the line breaks at all in the final output, then use this slightly shorter version:
TRIM(REGEX_REPLACE(SUBSTITUTE(SUBSTITUTE(Description, "&", "&"), " ", ""), "<t^>]*>", ""))
I kinda-sorta recreated your samples to make sure this would work correctly. {Cleaned} is the longer formula output, {Cleaned copy} is the shorter one.