

Indeed, views provide a very powerful way to scope and optimize access to data. However, they cannot be dynamically altered to achieve what I consider hyper-performant script processes. Here’s an example…
Imagine a table (a) with a view and when a record enters that view, search another table (b) that has 45,000 records in it for a single matching key so that a linkage can be established in (a) to (b).
I’m not an expert in all manners of Airtable scripting, but I think the only way to do this is to iterate across the 45000 records in table (b) to locate the record ID such that the linkage can be updated in table (a). Ironically, searching for discussions about this place me in the commentary mix here. And even then, I’m not sure I expressed the issues succinctly.
Two ideas come to mind when presented with this quandary -
-
Ideally, there should be a
searchRecordsAsync()method that uses the internal search capabilities to return a record (or record collection) given a field or record-level query. It would function largely like a dynamic view. -
Less than ideal, but likely even faster than search would be, a way to create and maintain arbitrary hash indices (like an inverted index) that can be loaded quickly instead of entire tables followed by a filter across all records. Indeed, we need a direct pointer much the way we used to find data in assembly code using registers circa 1982. :winking_face:
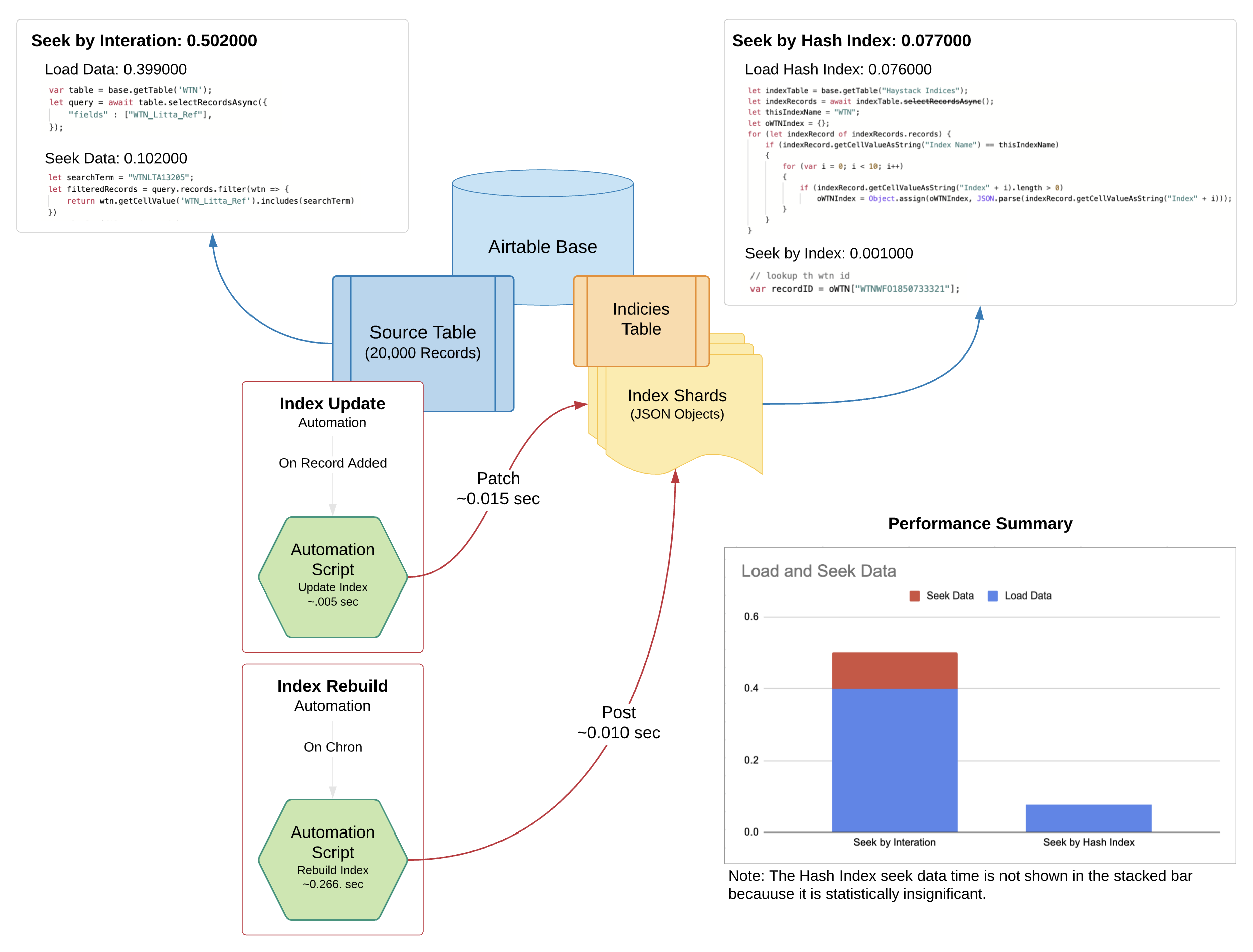
When presented with this challenge I use the approach shown below. It’s ideal in that it’s very fast and how fast depends on the data set and the types of lookups you need to perform. This example approach assumes we need only the record ID to establish a link, and it also assumes the link is based on a single key value. Performance, of course, will vary depending on the number of fields one might need access to for additional processing logic or record updates.
In any case, the analytics speak for themselves - this approach is 6.5 times faster for ~20,000 records and a sizeable 14.5 times faster for approximately 49,000 records. This is not surprising since Airtable typically bogs down the closer you get to 50,000 records.
But it’s important to realize that performance data like this is not linear and use cases vary greatly. However, if you have to perform lots of lookups across record sets, the performance gap between filtering across records and using a hash index begin to accumulate significantly.
Indices Table
Of deeper interest, I’m sure you’ll wonder what the Indices Table looks like.

The purpose of this table is simple - have a place to persist and update hash indices that can be accessed and queried very quickly.
It’s actually an extremely rudimentary approach - a single record holding an arbitrary hash index definition with long text fields representing the shards blocks. A Shard block is a JSON object of 100k bytes or less and this is necessary when creating indices involving large record collections because they cannot all fit inside a single long text cell. But even with this added complexity, the load and parse time of ten fully populated shards are still under 100 milliseconds; Airtable it seems is very fast when it comes to dealing with a single record. :winking_face:
And you might assume that the sort option in slectRecordsAsync() would provide some additional performance, but you’d be wrong in many scenarios - read this for more performance data.
Tell me what I missed.
