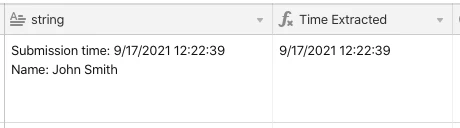
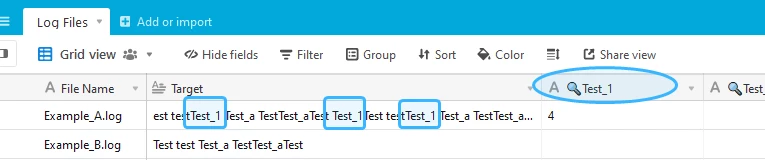
Hello everyone! We recently launched some exciting new additions to our formula field with three new regex (regular expression) functions:
REGEX_MATCH(string, regex)REGEX_EXTRACT(string, regex)REGEX_REPLACE(string, regex, replacement)
These functions can be used to match character combinations within text strings. For those interested, Airtable’s REGEX functions are implemented using the RE2 regular expression library.
You can learn more about these functions in this article or check out some example use cases shared in the posts below.