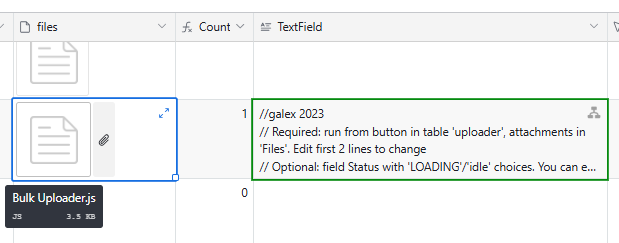
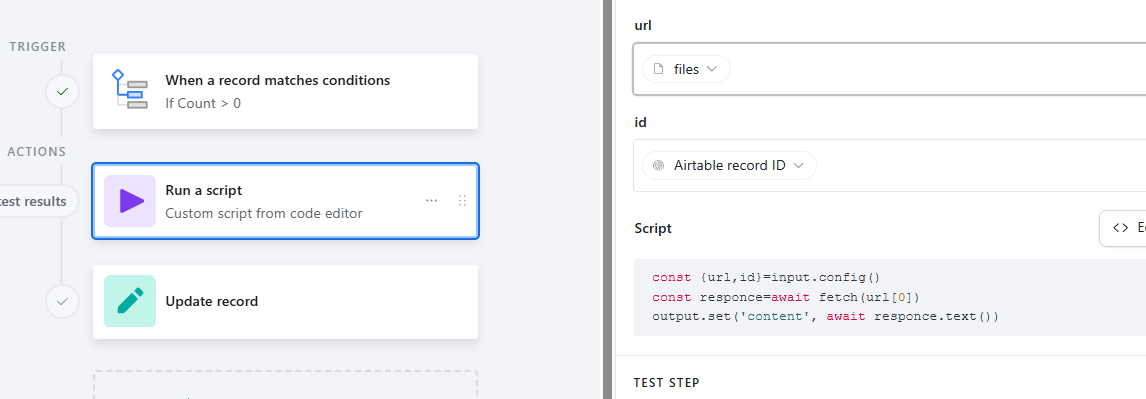
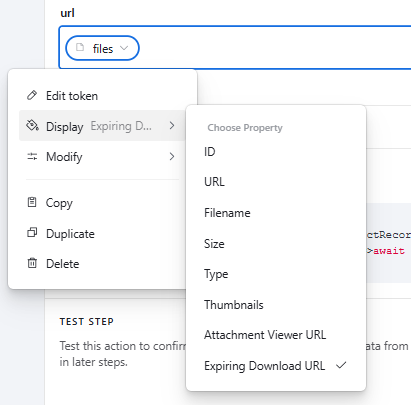
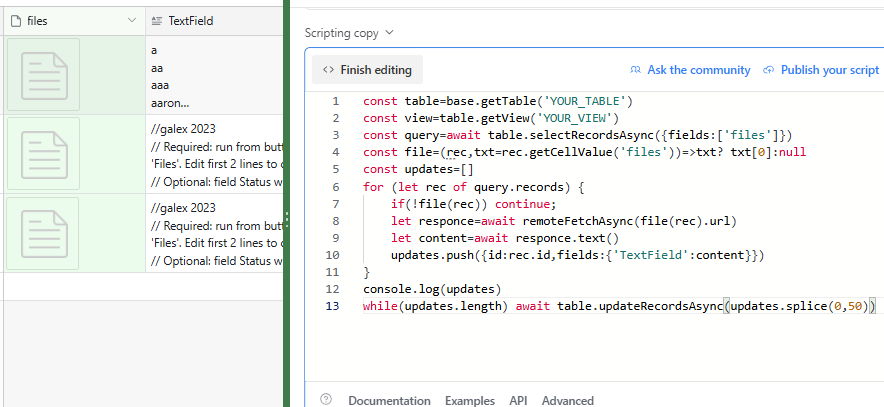
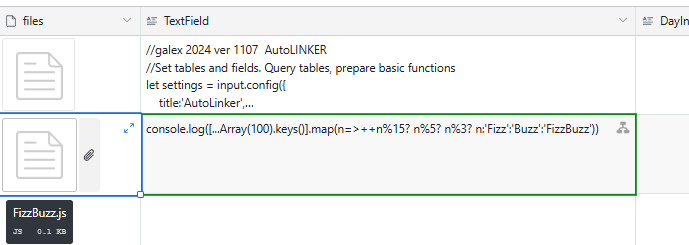
Can someone help with the coding of a script that converts the contents of attached .TXT files to a long Text filed?
We have an attachment field [TXT] that contains one text file per field. We wonder if it is possible to copy the contents of each text file to a long text filed?
I have see some notes on it, but we need scripting help to achieve it.
Thanks for any advice.
Kevin