Hi Airtable team,
I've encountered a Unicode-related issue with the “contains” filter in Airtable that leads to inconsistent and unexpected behavior when searching for certain characters – specifically, characters like “ü” stored as composed Unicode sequences.
🧪 Reproduction Scenario:
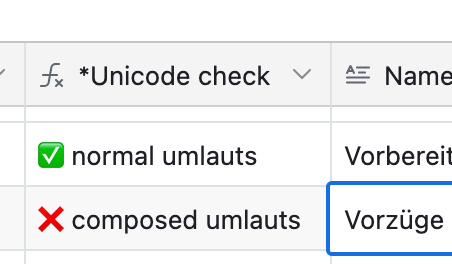
I'm importing records from an external API into Airtable. These records include names with the word “Vorzüge”, but the “ü” character is stored as a composed form:u (U+0075) + combining diaeresis ¨ (U+0308) – rather than as a single precomposed character ü (U+00FC).
Example records:
-
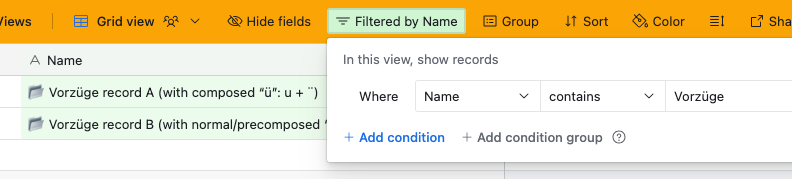
📂 Vorzüge record A (with composed “ü”:
u+¨) -
📂 Vorzüge record B (with normal/precomposed “ü”)
🧩 Problem:
-
When using the "contains" filter on the field and typing
"Vorzüge", only the record with the precomposed “ü” (U+00FC) is matched. -
The record with the composed form (U+0075 + U+0308) is not found, even though the text appears identical.
-
However, the global Airtable search (e.g., Cmd/Ctrl + K or in-table search) does return both records, suggesting that search uses Unicode normalization – while filters do not.
✅ Expected Behavior:
The “contains” filter should match Unicode-equivalent characters, even when they are technically stored using different code points (e.g., NFC vs. NFD normalization forms). If two characters look and behave the same, users reasonably expect them to match in filters.