I’m super excited to use the new input.fileAsync() API, but this is my first time working with file blobs in JavaScript, so I’m already scratching my head trying to figure out how to work with my file contents beyond the offerings of the API.
Disclaimer - this question has little to do with Airtable and the Scripting Block API itself; it’s basically just a plain old JavaScript question.
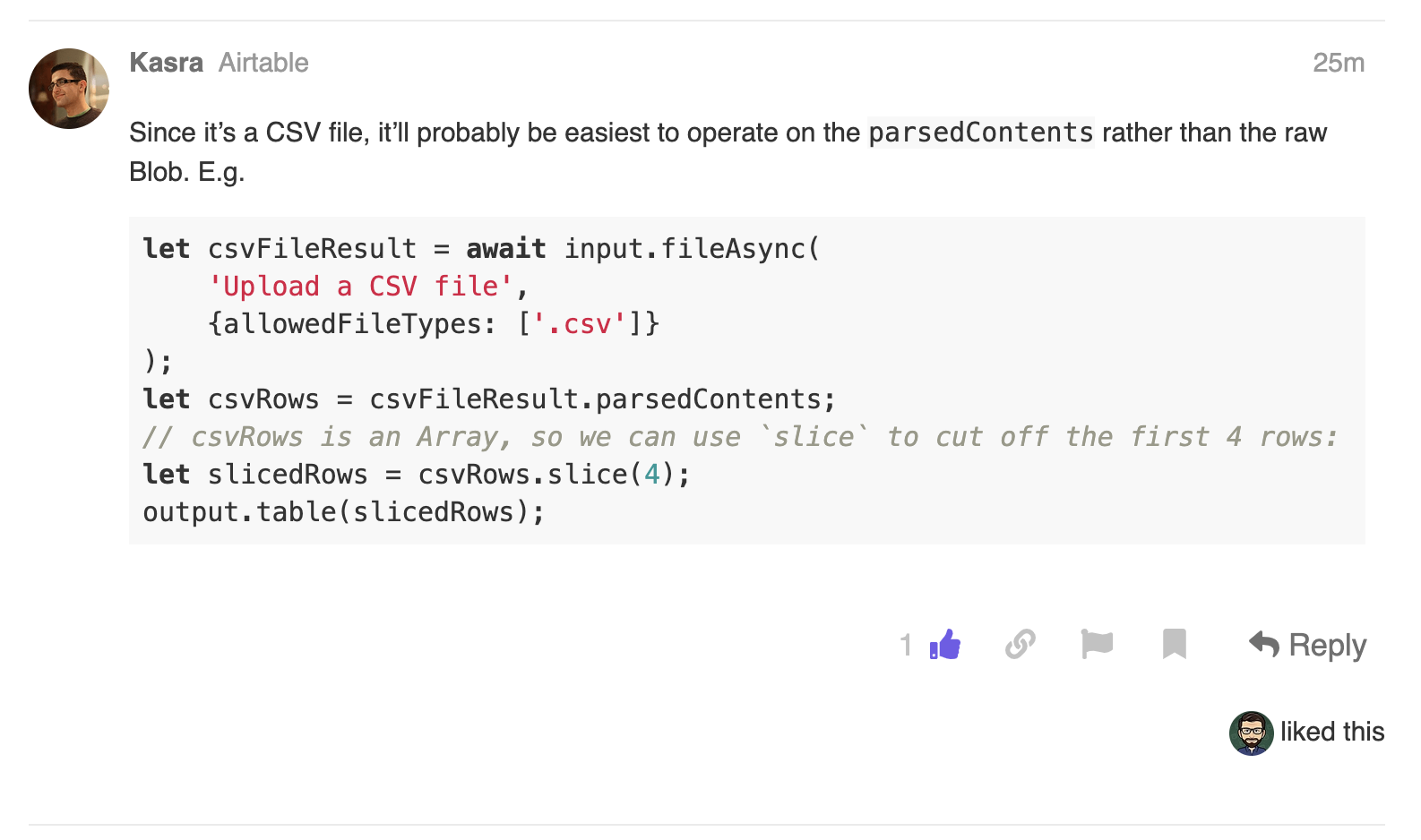
I already use the CSV import block to import bank statements to my budgeting base. However, my bank outputs 4 lines of identifier data before outputting the table of transactions – so I always have to manually open this CSV, remove those top 4 lines, save it, and then import it. I’ve been meaning to write a script to do this for me (was going to use ruby in MacOS), but Airtable’s new Scripting Block API is just in time to allow me to (hopefully) incorporate this into the import process!
So, I’m bringing in my file with
let fileObject = await input.fileAsync('Import a CSV', { allowedFileTypes: ['.csv'] });
The fileObject.parsedContents has 4 rows of content I don’t want before the table of transactions with a header row at the start of it. I’m really struggling to figure out how I can cut those 4 rows.
The only Intellisense option made available on fileObject.file that looks like it might allow me to do what I need to do is the Blob.slice() method – but according to documentation, this operates on bytes, and not on text content or file rows.
I’m continuing to research and asking elsewhere on the internet, but I figured I’d ask here too if anyone would be kind enough to help me tackle this and understand better how to work with blobs and bytes in JavaScript :slightly_smiling_face: