Hi,
My problem is that I’m trying to extract some data (Name, Address(city, street,zip), order number, etc..) from filled form files.
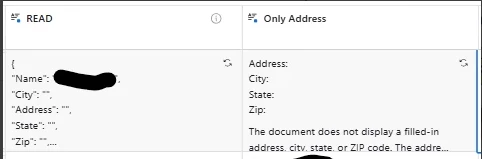
In ~50% it works OK, in rest it cannot retrieve Address-related data. Other data retrieved OK.
i tried to change prompt and model - result is the same or worse. When I changed prompt to very simple - it was able to get Addrees in ¼ of records where it failed to do it before.
The most strange thing - my first record in table is where it cannot pull address
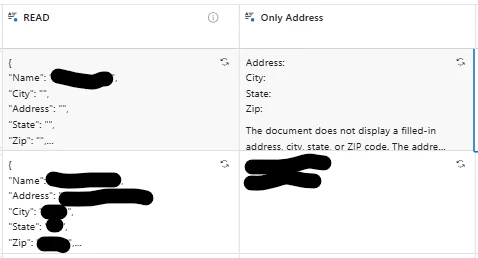
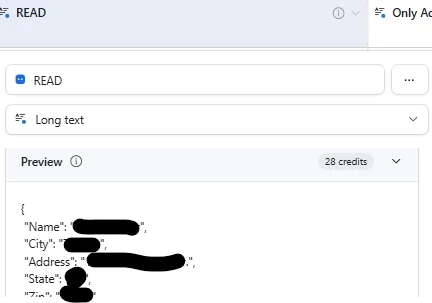
When I set up any of these fields, in preview, output of this file (from first record) is OK, with address, as it shoould be, on both fields. I changed order for ‘City’, ‘Address’ on purpose, to be sure bad result does not ‘cached’ anywhere, but still the same result. Preview is okay. Ouput is not. Other info is OK, like Name. Only Address-related data is empty.
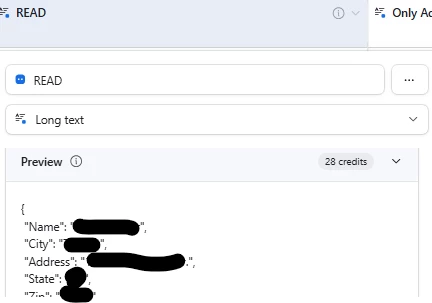
Preview is OK.