First Airtable. is. awesome. I which I knew about it before to help organize my work.
Something I feel is missing though is a more powerful approach to deal with string-based functions.
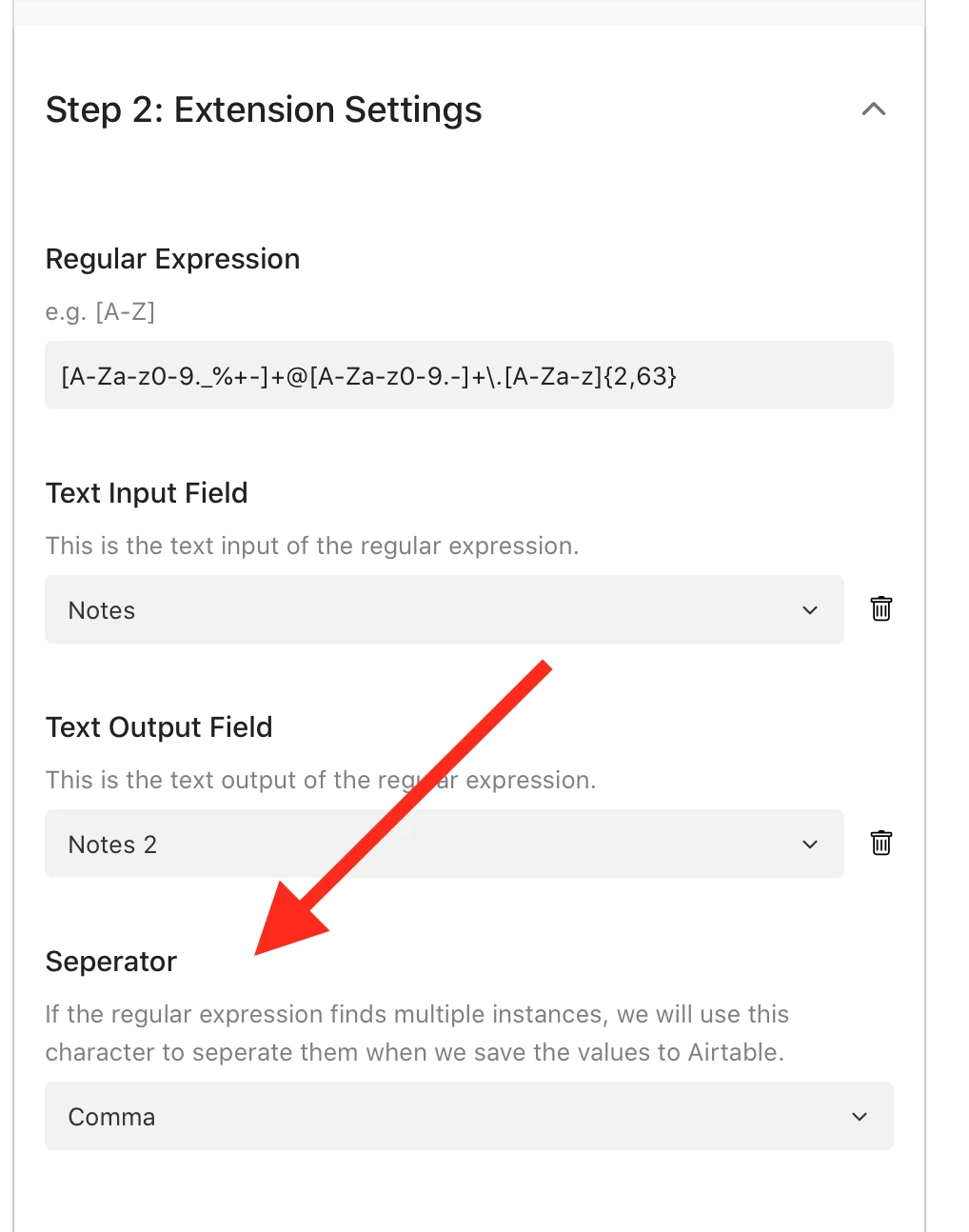
For instance, it would be great to be able to use RegEx in the FIND or SUBSTITUTE functions.
A use case, e.g., is the extraction of part of a URL to use it as a primary key. It would allow me to name automatically a bunch of website links I wanna store.
I.e., there’s a REGEXEXTRACT function in Google Sheet, this is extremely useful for numerous of applications.